DMA(Direct Nemory Access) Remapping是一种用来限制硬件设备只能使用DMA访问预先分配的内存区域(domain or physical memory regions)的技术。DMA Remapping会把DMA请求里的地址转化成正确的物理内存地址,同时还会检查设备是否允许访问指定的内存。请看下图:
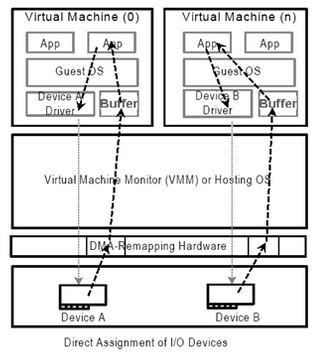
虚拟机的操作系统(Guest OS)所提供的物理地址称为Guest Physical Address (GPA) ,它不一定与实际的物理地址一致,也就是Host Physical Address (HPA),而DMA技术则要求访问真实的物理地址。DMA Remapping技术可以把Guest OS提供的GPA转化成HPA,然后数据就可以直接发送到Guest OS的缓冲区(buffer)了。
主机平台(host platform)可以支持一个或多个DMA remapping硬件单元(hardware unit),每个硬件单元remapping从它控制的作用域内发出的DMA remapping请求。主机固件(BIOS)需要把每个DMA remapping硬件单元报给系统软件(比如操作系统)。
DMA remapping硬件单元使用source-id来标示发出DMA请求的设备。对一个PCI Express设备,source-id就是resource identifier:
________________________________________________________
|____Bus(8 bits)_________|__Device(5 bits)|_func(3 bits)_|
Root-entry作为最顶层的数据结构,会把某特定PCI总线上的设备映射到对应的domain。一个context-entry会把一个地址总线上的某个具体设备映射到对应的domain。参考下图:
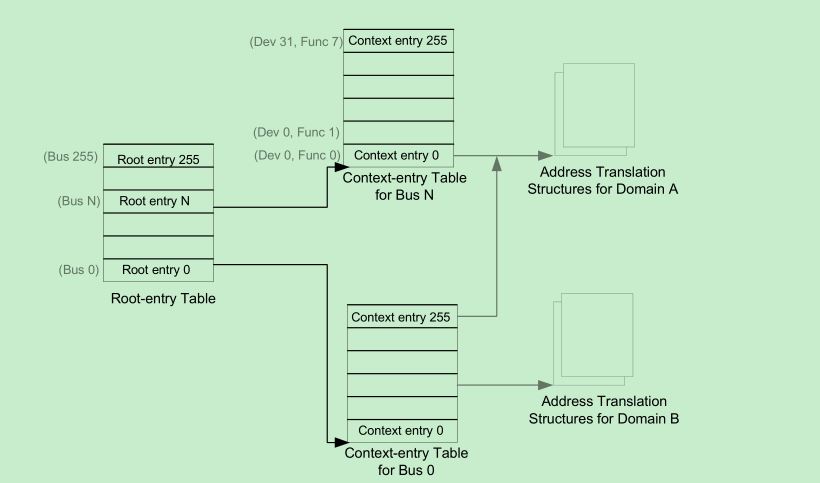
每个root-entry会有一个指向一个context-entry的表的指针,而每个context-entry则会包含如何用来进行地址转化的结构。