这篇笔记摘自Professional CUDA C Programming:
A typical heterogeneous compute node nowadays consists of two multicore CPU sockets and two or more many-core GPUs. A GPU is currently not a standalone platform but a co-processor to a CPU. Therefore, GPUs must operate in conjunction with a CPU-based host through a PCI-Express bus. That is why, in GPU computing terms, the CPU is called the host and the GPU is called the device.
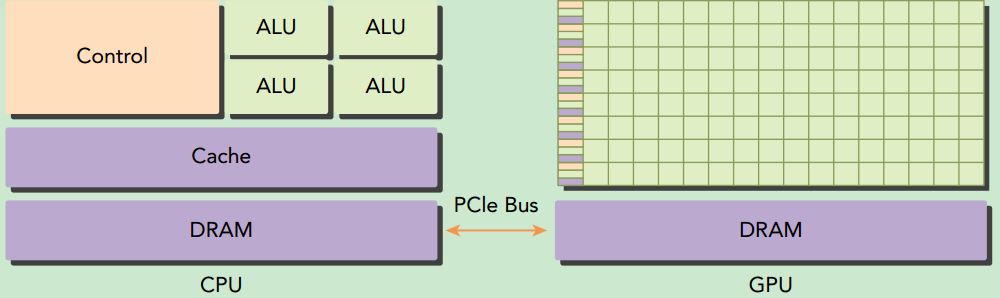
A heterogeneous application consists of two parts:
➤ Host code
➤ Device code
Host code runs on CPUs and device code runs on GPUs. An application executing on a heterogeneous platform is typically initialized by the CPU. The CPU code is responsible for managing the environment, code, and data for the device before loading compute-intensive tasks on the device.There are two important features that describe GPU capability:
➤ Number of CUDA cores
➤ Memory size
Accordingly, there are two different metrics for describing GPU performance:
➤ Peak computational performance
➤ Memory bandwidth
Peak computational performance is a measure of computational capability, usually defined as how many single-precision or double-precision floating point calculations can be processed per second. Peak performance is usually expressed in gflops (billion floating-point operations per second) or tflops (trillion floating-point calculations per second). Memory bandwidth is a measure of the ratio at which data can be read from or stored to memory. Memory bandwidth is usually expressed in gigabytes per second, GB/s.