使用perf record命令可以profile应用程序 (编译程序要使用-g,推荐使用-g -O2) :
perf record program [args]
或者在程序启动以后,使用-p pid选项:
perf record -p pid
默认情况下,信息会存在perf.data文件里,使用perf report命令可以解析这个文件:

哪些函数占用CPU比较多,一目了然。
另外,在使用perf record时可以加--call-graph dwarf选项:
--call-graph
Setup and enable call-graph (stack chain/backtrace) recording, implies -g.
Default is "fp".
采样结果如下:
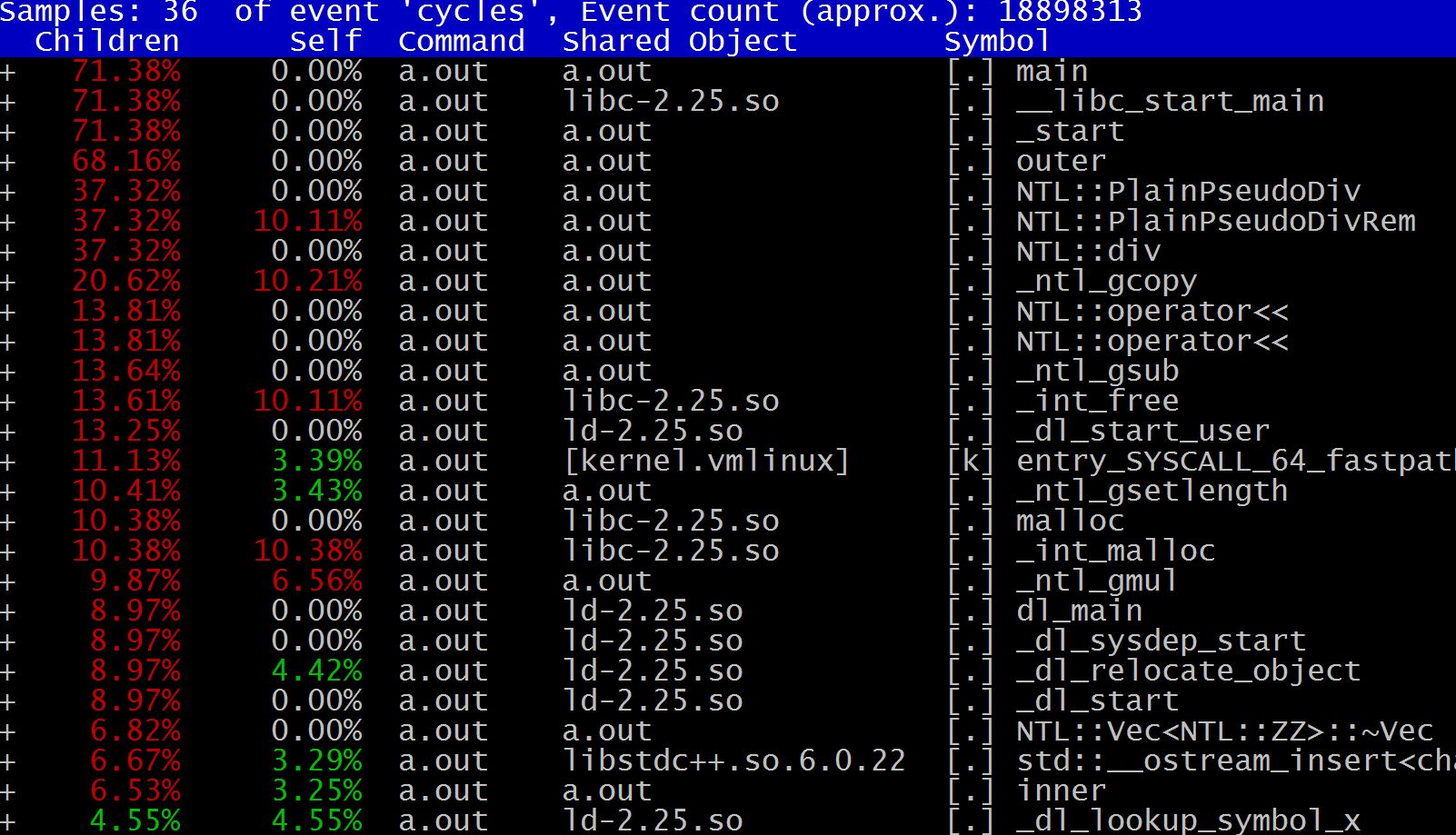
关于Children和Self的含义,perf wiki给了一个详尽的解释。以下列代码为例:
void foo(void) {
/* do something */
}
void bar(void) {
/* do something */
foo();
}
int main(void) {
bar()
return 0;
}
Self表示函数本身的overhead:如果foo函数的overhead占60%,那么bar的Self overhead就是40%(刨除foo所占部分)。因为foo和bar都是main的子函数,所以二者的overhead都要计算入main的Children overhead。
对于采用--call-graph dwarf选项生成的perf.data做出的火焰图如下:
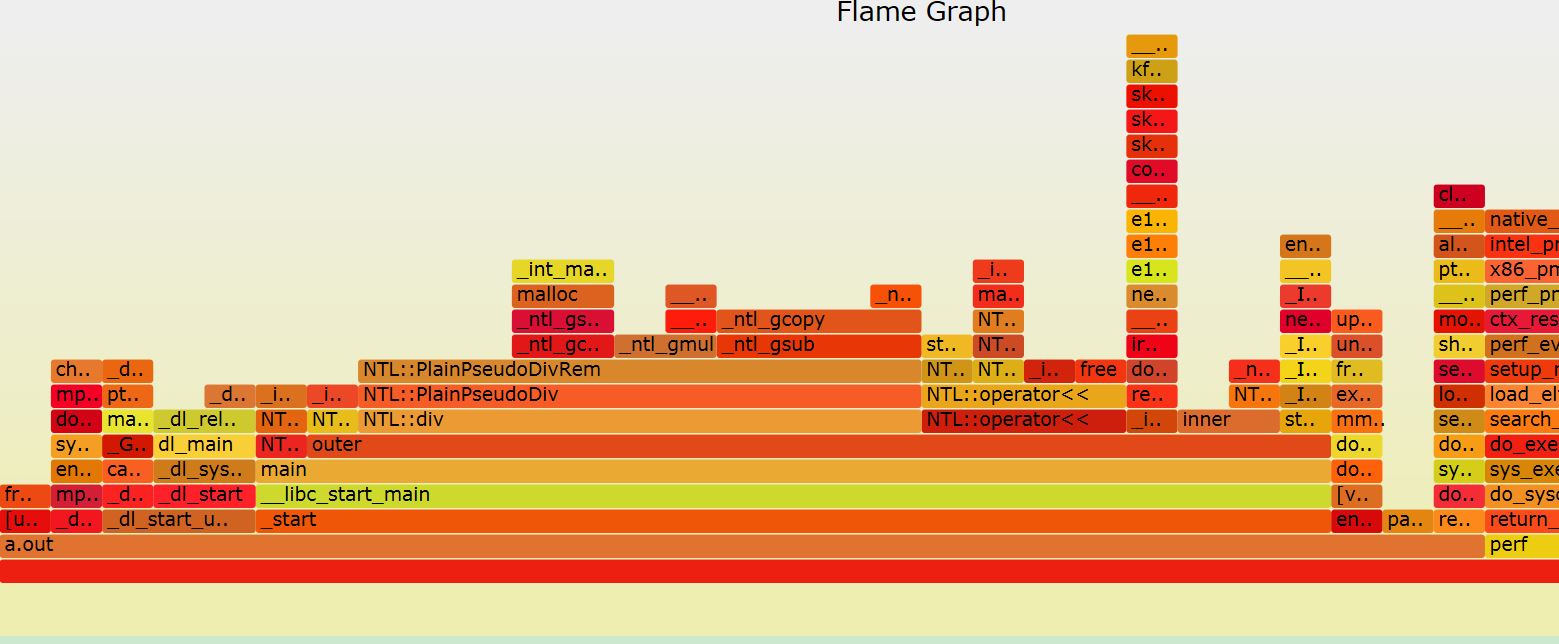 可以看到显示了完整的函数调用栈。
可以看到显示了完整的函数调用栈。