Apache Spark(以下简称Spark)是一个快速的,通用的集群计算平台(Apache Spark is a cluster computing platform designed to be fast and general-purpose),它由多个紧密结合的构件组成:
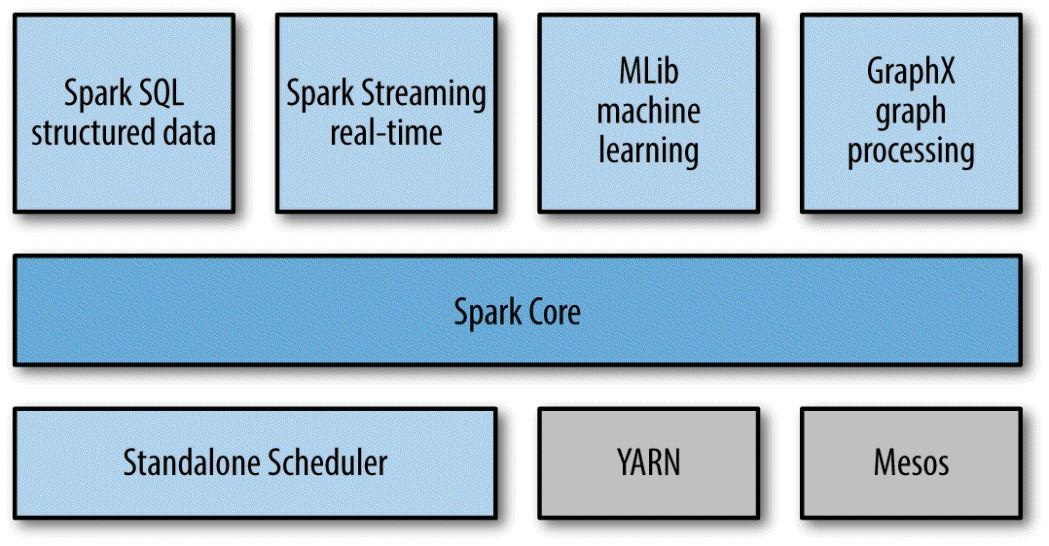
Spark Core包含Spark的最基本的功能:任务调度,内存管理,故障恢复,存储系统的交互,等等。
Spark SQL是用来处理结构化数据的程序包。它不仅允许使用SQL,HQL(Hive Query Language)来查询数据,并且支持多种数据源:Hive tables,Parquet和JSON。
Spark Streaming用来处理实时的数据流。
MLib是一个提供了很多机器学习算法的库。
GraphX是一个提供操作图表以及对图表进行并行计算的库。
Spark除了自带了一个简单的Cluster Manager:Standalone Scheduler以外,也支持Hadoop YARN和Apache Mesos。
Spark可以把存储在Hadoop Distributed File System(HDFS)或其它支持Hadoop API的存储系统(包含你本地文件系统,Amazon S3,Cassandra,Hive,HBase等)上的文件转化成分布式数据集(distributed datasets)。要注意,Hadoop对于Spark来说不是必不可少的,只要存储系统实现Hadoop API即可。
参考资料:
《Learning Spark》。