这篇笔记摘自Professional CUDA C Programming:
When a kernel function is launched from the host side, execution is moved to a device where a large number of threads are generated and each thread executes the statements specified by the kernel function. CUDA exposes a thread hierarchy abstraction to enable you to organize your threads. This is a two-level thread hierarchy decomposed into blocks of threads and grids of blocks:
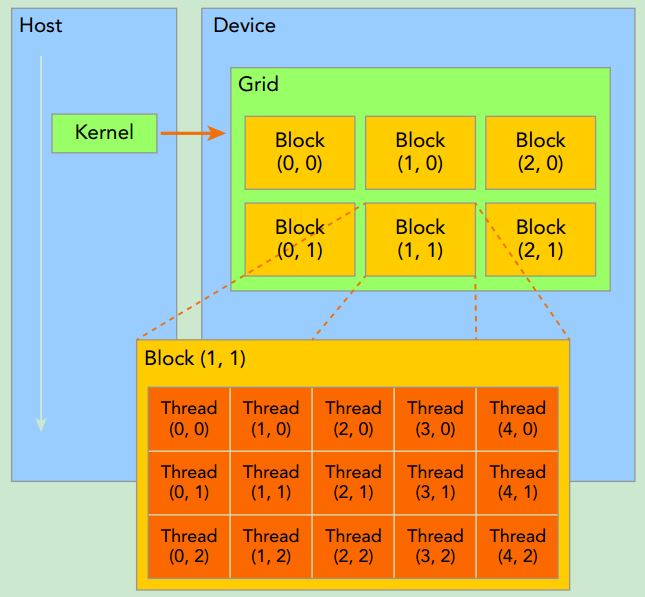
All threads spawned by a single kernel launch are collectively called a grid. All threads in a grid share the same global memory space. A grid is made up of many thread blocks. A thread block is a group of threads that can cooperate with each other using:
➤ Block-local synchronization
➤ Block-local shared memory
Threads from different blocks cannot cooperate.
Threads rely on the following two unique coordinates to distinguish themselves from each other:
➤ blockIdx (block index within a grid)
➤ threadIdx (thread index within a block)
These variables appear as built-in, pre-initialized variables that can be accessed within kernel functions. When a kernel function is executed, the coordinate variables blockIdx and threadIdx are assigned to each thread by the CUDA runtime. Based on the coordinates, you can assign portions of data to different threads. The coordinate variable is of type uint3, a CUDA built-in vector type, derived from the basic integer type.CUDA organizes grids and blocks in three dimensions. The dimensions of a grid and a block are specifed by the following two built-in variables:
➤ blockDim (block dimension, measured in threads)
➤ gridDim (grid dimension, measured in blocks)
These variables are of type dim3, an integer vector type based on uint3 that is used to specify dimensions. When defining a variable of type dim3, any component left unspecified is initialized to 1.
blockIdx&threadIdx是uint3类型,含义是坐标,所以下标从0开始;blockDim&gridDim是dim3类型,含义是维度,即用来计算block中有多少个thread,当前grid中包含多少个block,因此默认值是1。
There are two distinct sets of grid and block variables in a CUDA program: manually-defined dim3 data type and pre-defined uint3 data type. On the host side, you define the dimensions of a grid and block using a dim3 data type as part of a kernel invocation. When the kernel is executing, the CUDA runtime generates the corresponding built-in, pre-initialized grid, block, and thread variables, which are accessible within the kernel function and have type uint3. The manually-defined grid and block variables for the dim3 data type are only visible on the host side, and the built-in, pre-initialized grid and block variables of the uint3 data type are only visible on the device side.
It is important to distinguish between the host and device access of grid and block variables. For example, using a variable declared as block from the host, you define the coordinates and access them as follows:
block.x, block.y, and block.z
On the device side, you have pre-initialized, built-in block size variable available as:
blockDim.x, blockDim.y, and blockDim.z
In summary, you define variables for grid and block on the host before launching a kernel, and access them there with the x, y and z fields of the vector structure from the host side. When the kernel is launched, you can use the pre-initialized, built-in variables within the kernel.下面这
3页摘自Learn CUDA In An Afternoon: