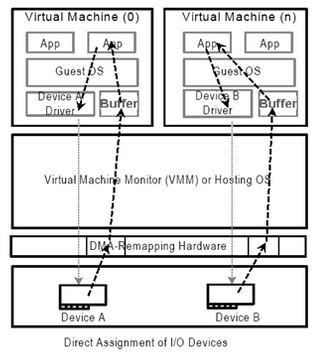
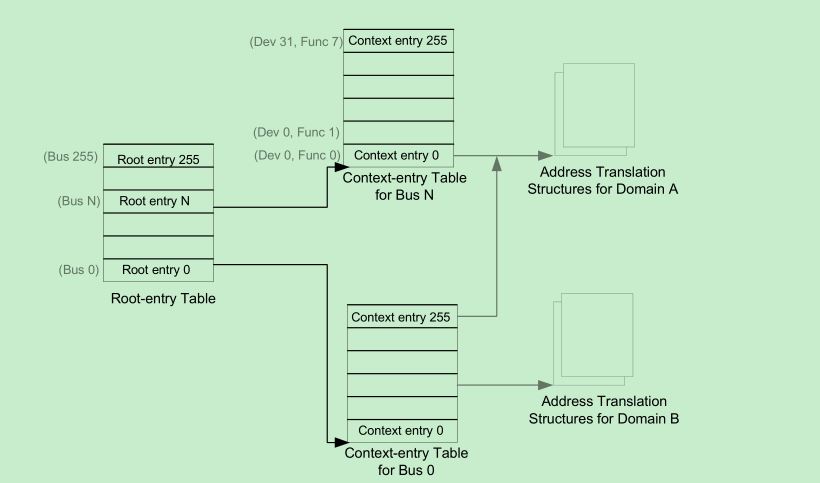
硬件虚拟化(hardware virtualization)可以创建出多个系统虚拟机实例(system virtual machine instance),这些虚拟机可以运行整个操作系统(包括它们的内核)。硬件虚拟化分为以下几种:
a)Full virtualization - binary translation:提供一个由虚拟化硬件部件组成完整的虚拟化系统,可以在上面安装一个不需修改的,完整的操作系统。这项技术结合了直接的处理器执行和必要时指令的二进制转化(binary translation)。
b)Full virtualization - hardware-assisted:提供一个由虚拟化硬件部件组成完整的虚拟化系统,可以在上面安装一个不需修改的,完整的操作系统。这项技术利用了处理器的支持,使得执行虚拟机更加有效率(比如AMD-V和Intel-VT扩展)。
c)Paravirtualization:提供一个支持接口(interface)的虚拟系统,虚拟机操作系统(guest OS)利用这个接口就可以有效地利用宿主机(host)资源(通过hypercalls),而不需要所有组件的完全虚拟化。
还有一种hybrid virtualization,利用hardware-assisted virtualization加上一些高效的paravirtualization调用,可以提供更好的性能(performance)。
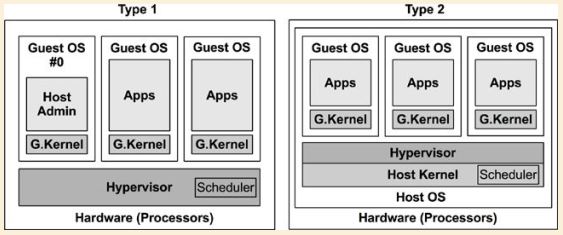
Hypervisor(或被称为Virtual Machine Monitor (VMM))是用来创建虚拟机的,它可以由软件(software),硬件(hardware)或固件(firmware)实现。有2种类型的hypervisor,请参考下图:
类型1)这种hypervisor直接运行在处理器上 (例如:hyper-V,KVM) ,也被称之为native hypervisor或bare-metal hypervisor。Hypervisor的管理工作是通过一个享有特权模式的guest OS来进行(在上图中,为Guest OS #0),这个guest OS可以创建和启动其它的guest OS。
类型2)这种hypervisor运行在宿主机操作系统上 (例如:VirtualBox) 。由宿主机操作系统负责管理hypervisor和启动新的guest OS。
参考资料:
Systems Performance: Enterprise and the Cloud。