My Operating System is Windows 7, so this tutorial may be little difference for your environment.
Firstly, you should install Scala 2.10.x version on Windows to run Spark, else you would get errors like this:
Exception in thread "main" java.lang.NoSuchMethodError: scala.collection.immutable.HashSet$.empty()Lscala/collection/immutable/HashSet;
at akka.actor.ActorCell$.<init>(ActorCell.scala:305)
at akka.actor.ActorCell$.<clinit>(ActorCell.scala)
at akka.actor.RootActorPath.$div(ActorPath.scala:152)
......
Please refer this post.
Secondly, you should install Scala plugin and create a Scala project, you can refer this document: Getting Started with Scala in IntelliJ IDEA 14.1.
After all the above steps are done, the project view should like this:
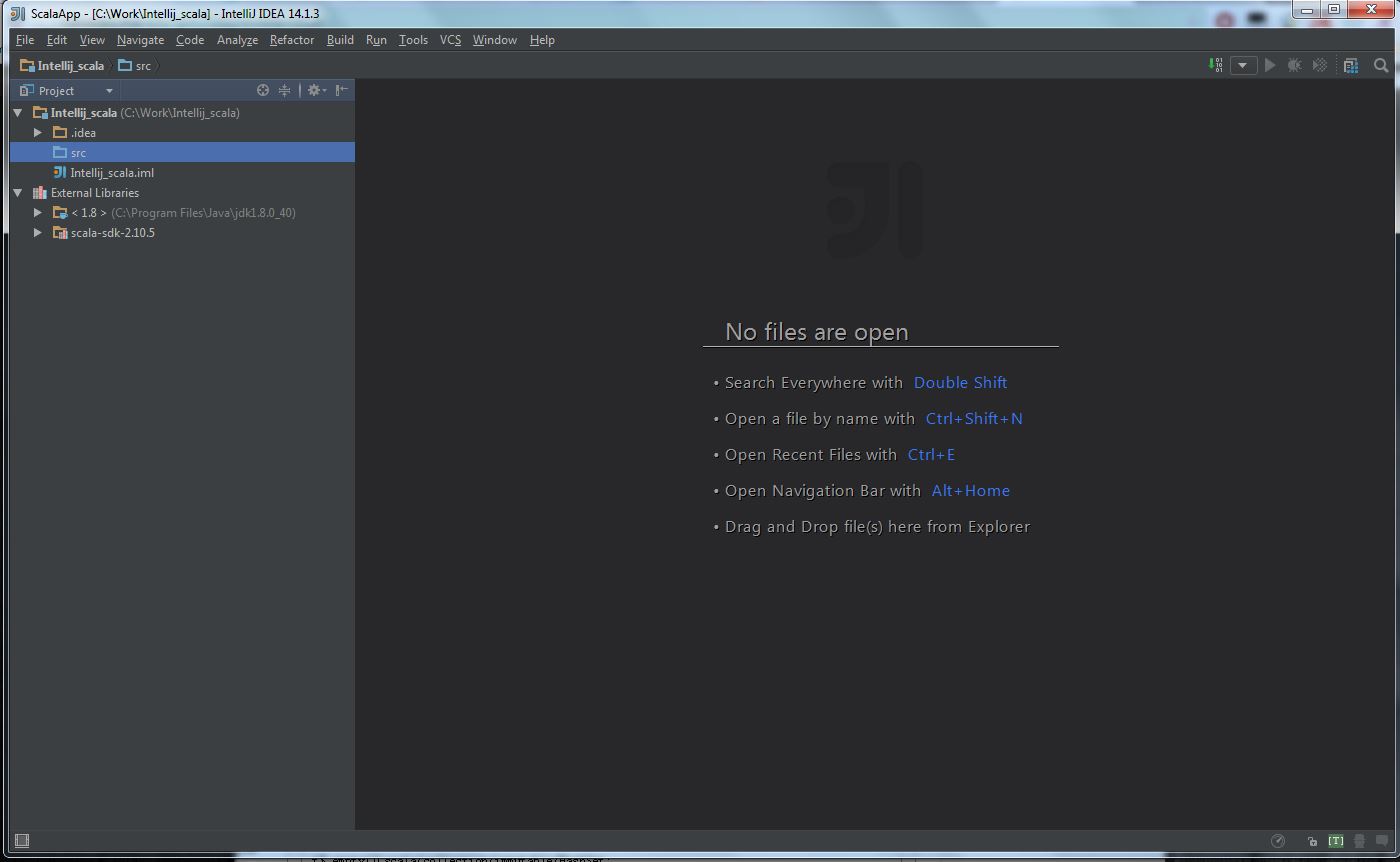
Then follow the next steps:
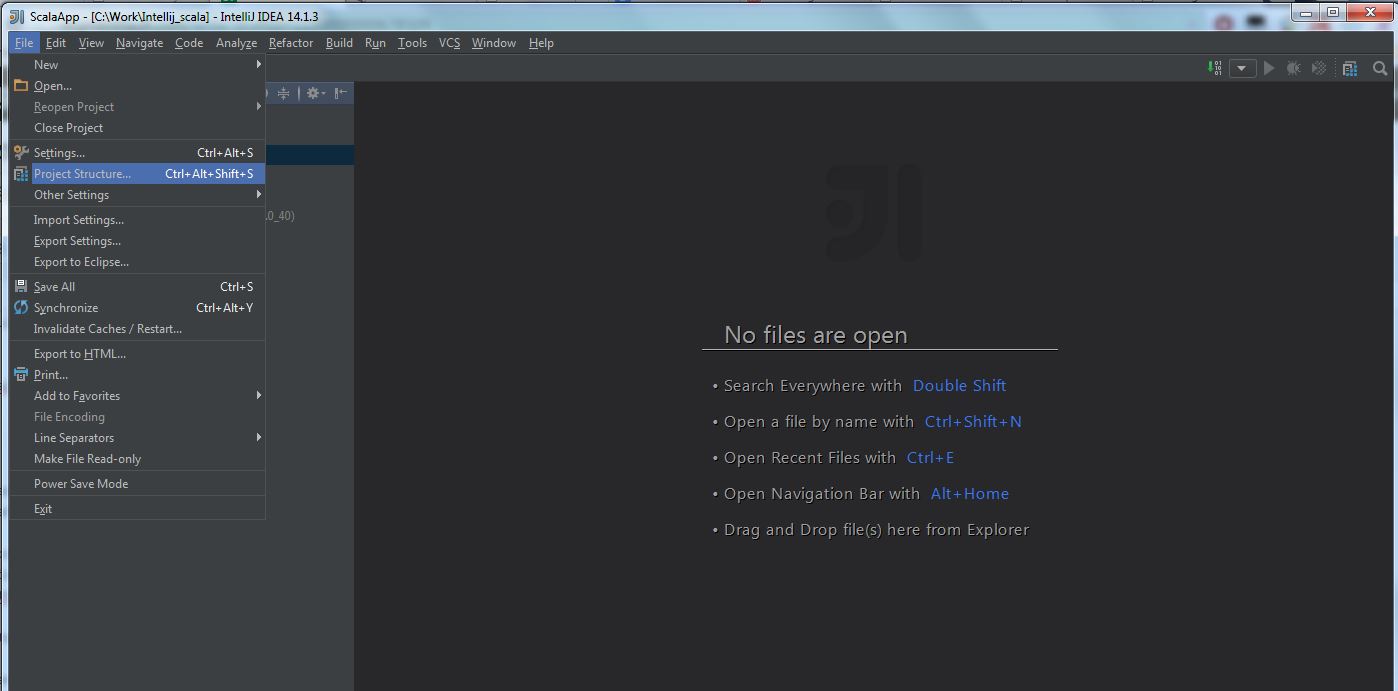
(1) Select “File” -> “Project Structure“:
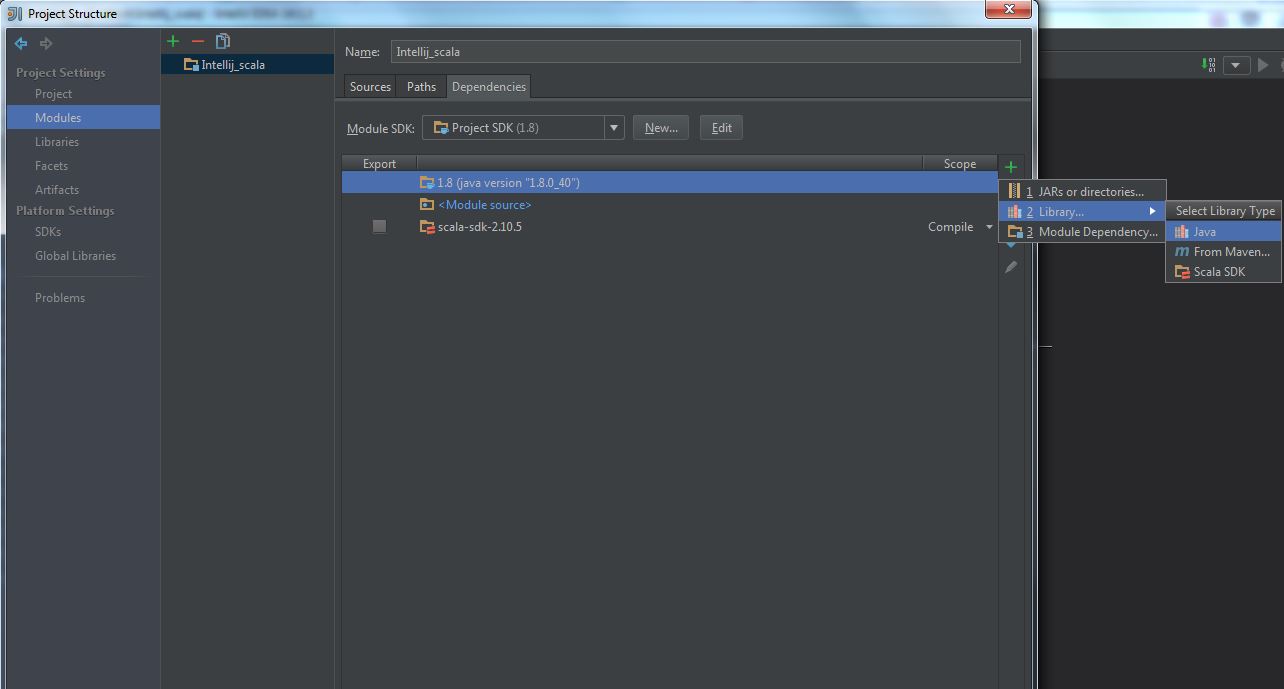
(2) Select “Modules” -> “Dependencies” -> “+” -> “Library” -> “Java“:
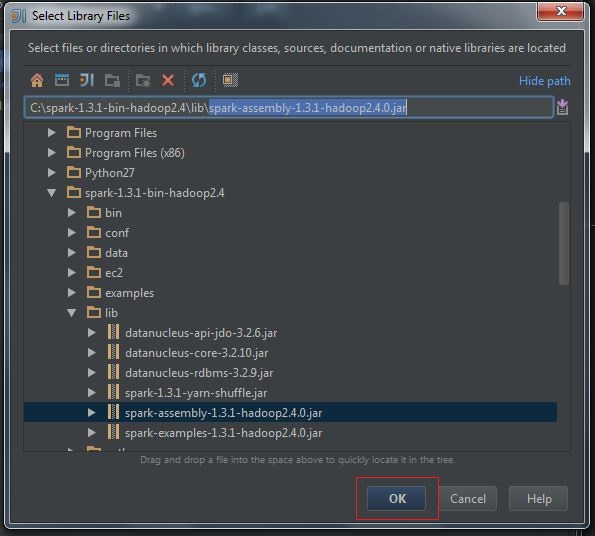
(3) Select spark-assembly-x.x.x-hadoopx.x.x.jar, press OK:
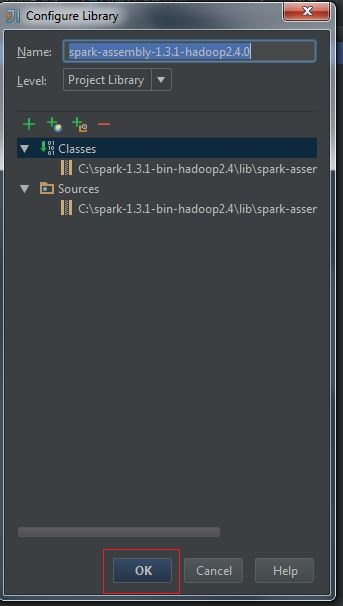
(4) Configure Library, press OK:
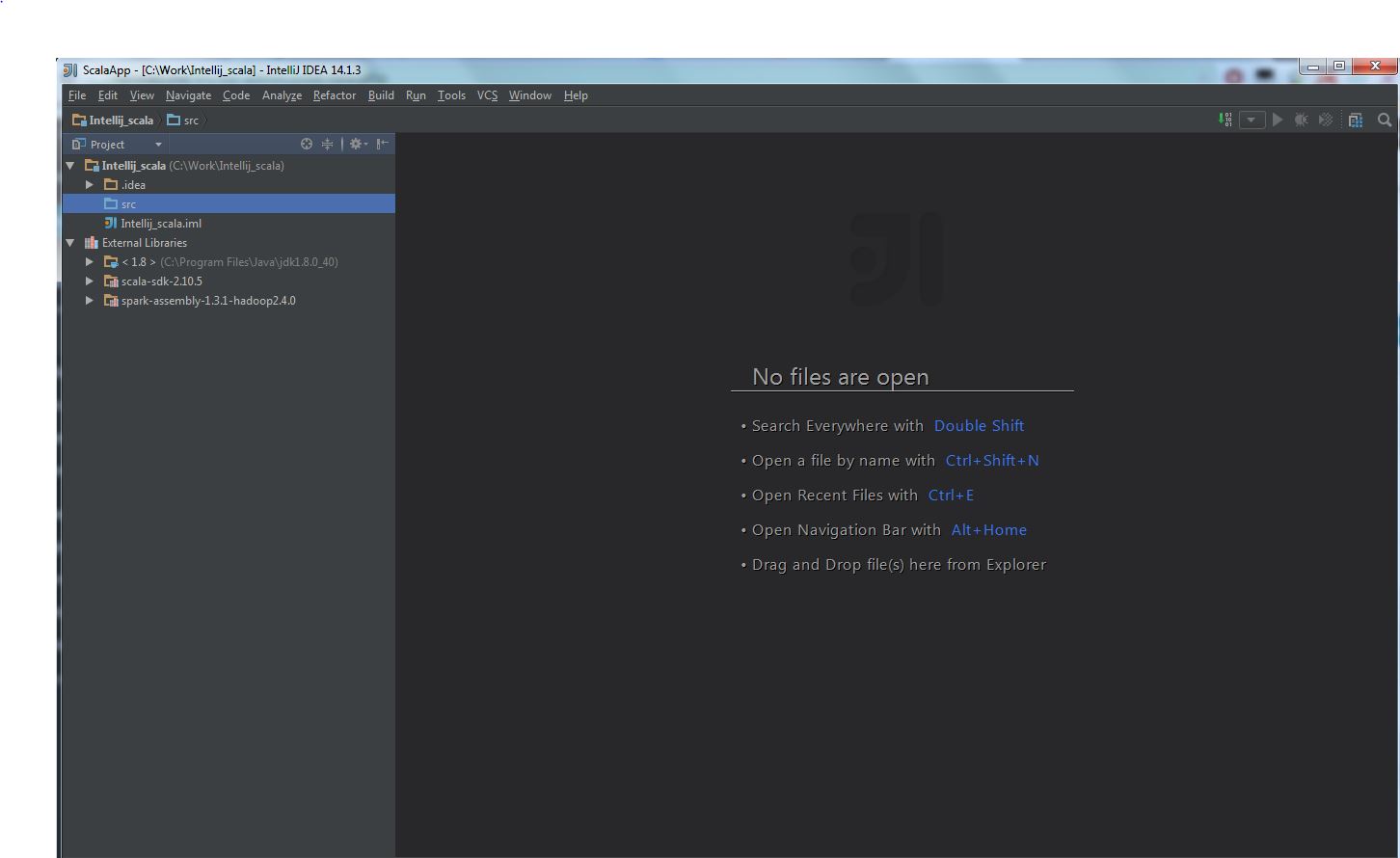
(5) The final configuration likes this:
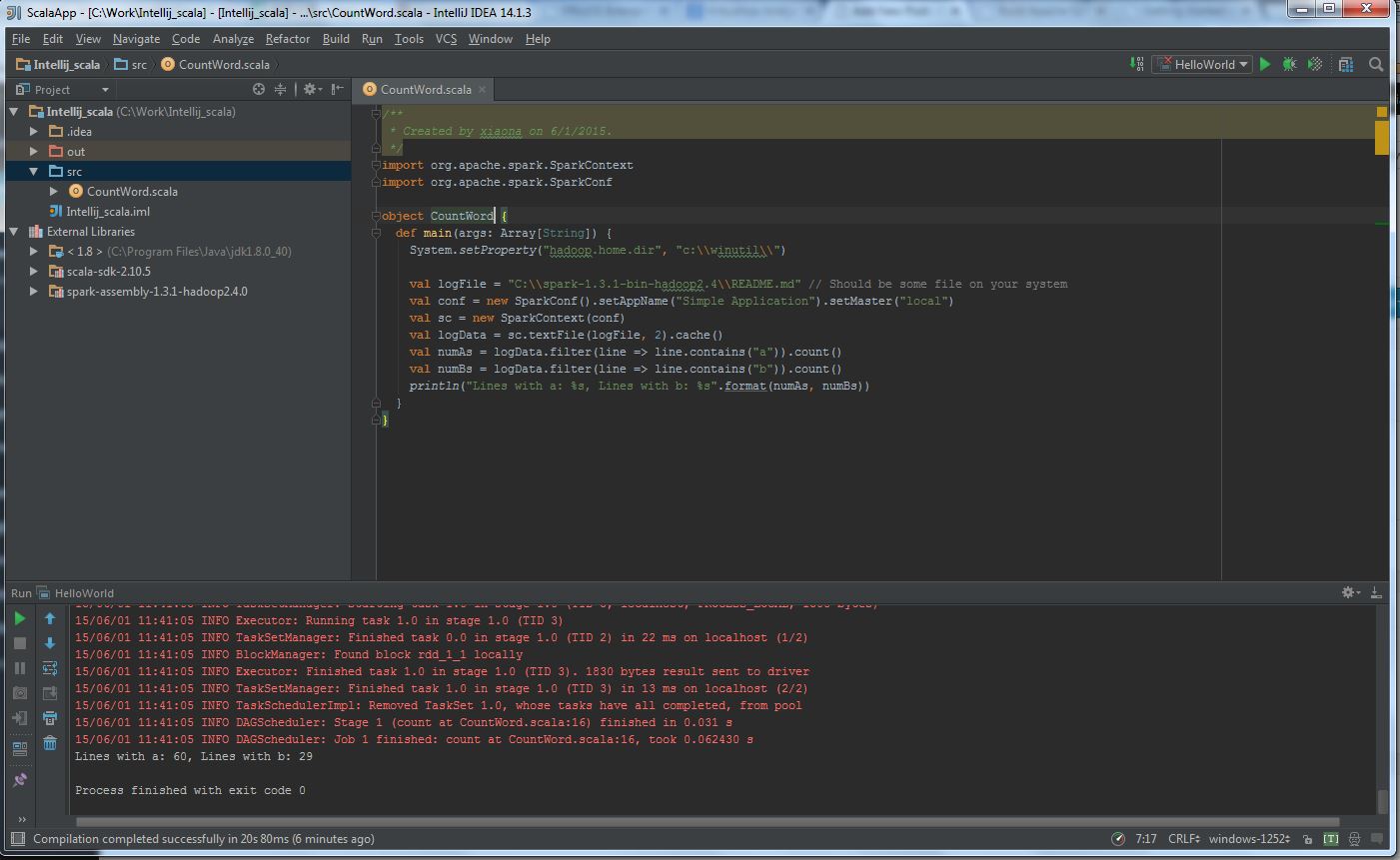
(6) Write a simple CountWord application:
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
object CountWord{
def main(args: Array[String]) {
System.setProperty("hadoop.home.dir", "c:\\winutil\\")
val logFile = "C:\\spark-1.3.1-bin-hadoop2.4\\README.md" // Should be some file on your system
val conf = new SparkConf().setAppName("Simple Application").setMaster("local")
val sc = new SparkContext(conf)
val logData = sc.textFile(logFile, 2).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println("Lines with a: %s, Lines with b: %s".format(numAs, numBs))
}
}
Please notice “System.setProperty("hadoop.home.dir", "c:\\winutil\\")” , You should downloadwinutils.exe and put it in the folder: C:\winutil\bin. For detail information, you should refer the following posts:
a) Apache Spark checkpoint issue on windows;
b) Run Spark Unit Test On Windows 7.
(7) The final execution likes this:
The following part introduces creating SBT project:
(1) Select “New project” -> “Scala” -> “SBT“, then click “Next“:
(2) Fill the “project name” and “project location“, then click “Finish“:
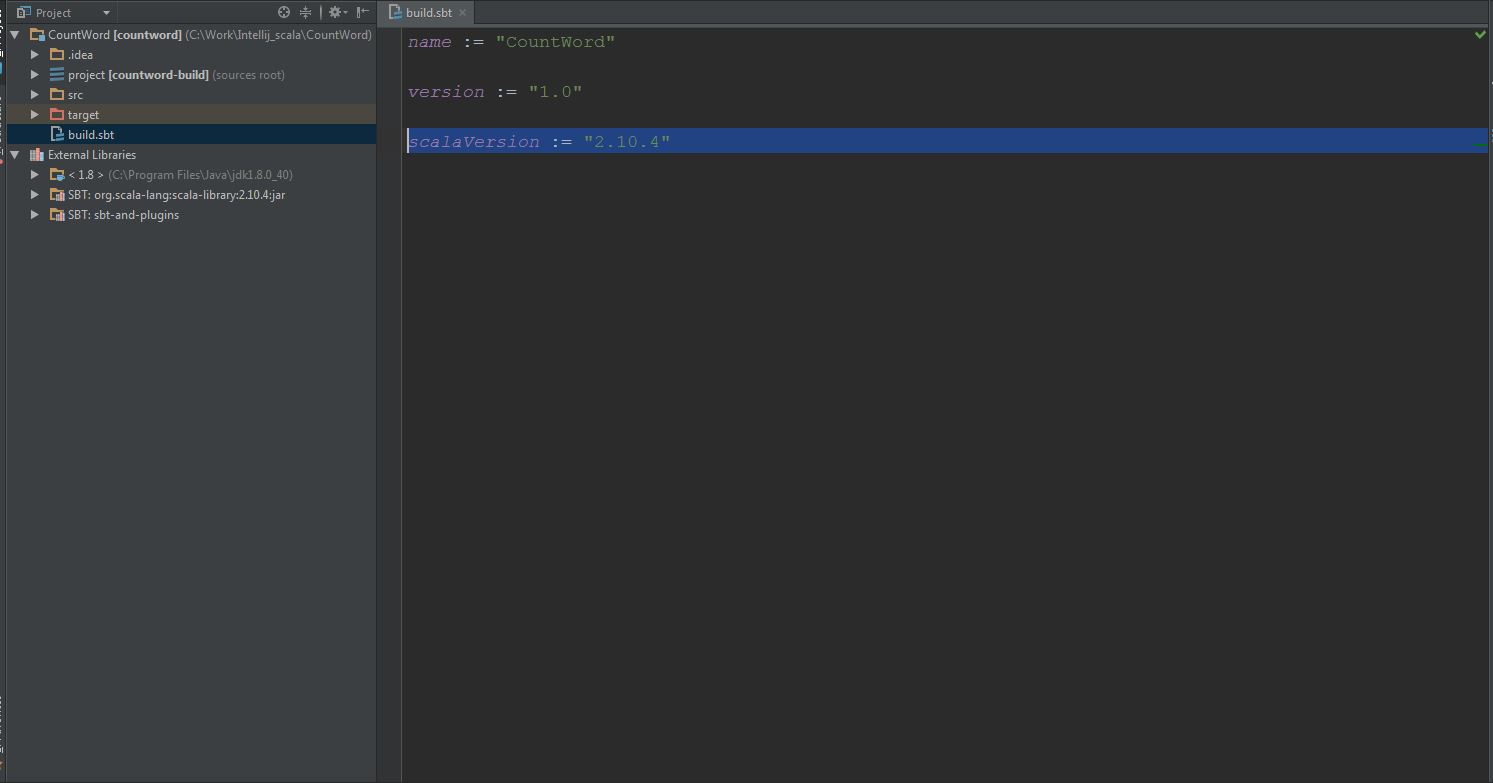
(3) In Windows, modify the scala version to 2.10.4 in build.sbt:
(4) Add spark package and create an scala object in “src -> main -> scala-2.10” folder, the final file layout likes this: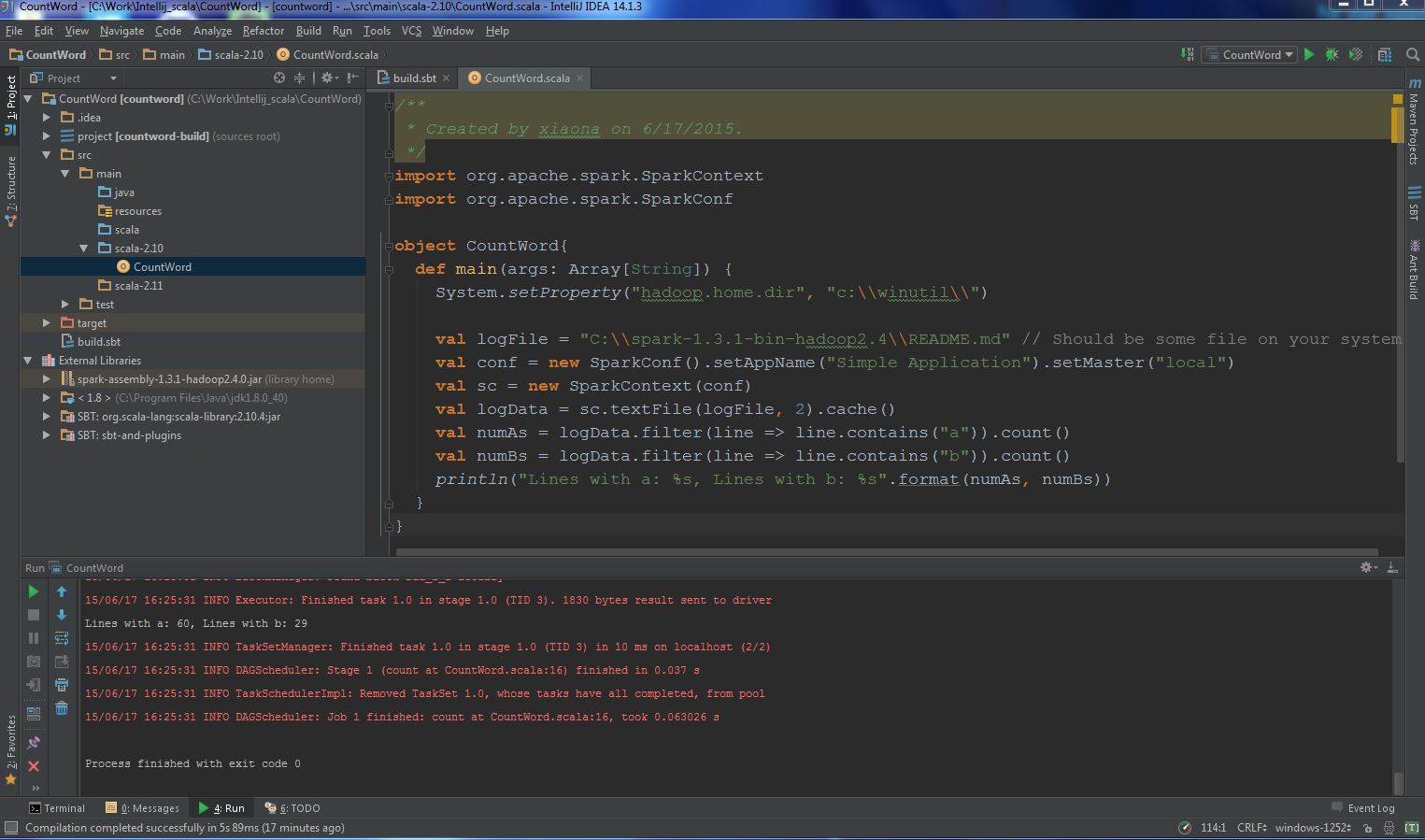 (5) Run it!
(5) Run it!
You can also build a jar file:
“File” -> “Project Structure” -> “Artifacts“, then select options like this:
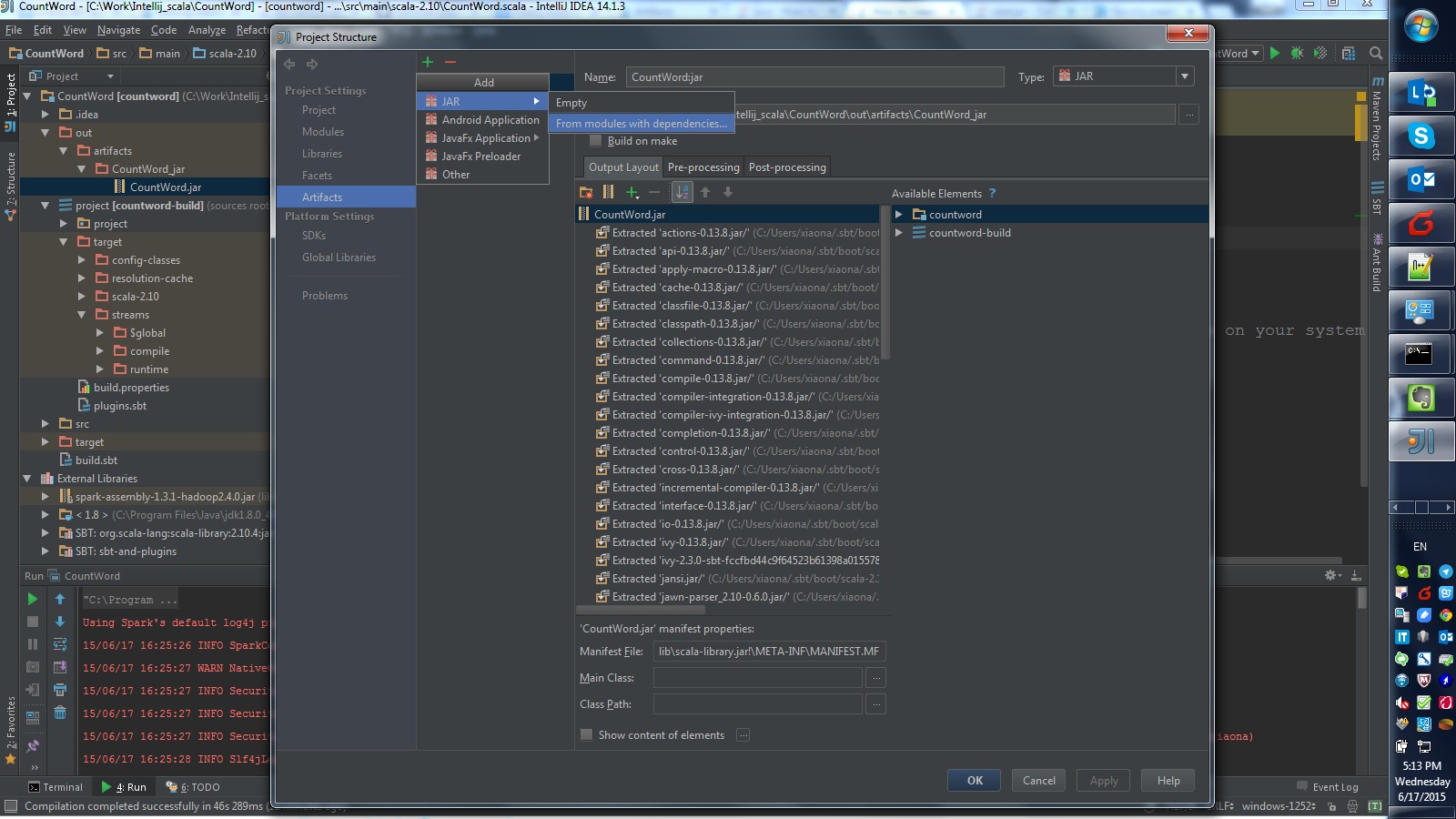
Refer this post in stackoverflow.
Then using spark-submit command execute jar package:
C:\spark-1.3.1-bin-hadoop2.4\bin>spark-submit --class "CountWord" --master local
[4] C:\Work\Intellij_scala\CountWord\out\artifacts\CountWord_jar\CountWord.jar
15/06/17 17:05:51 WARN NativeCodeLoader: Unable to load native-hadoop library fo
r your platform... using builtin-java classes where applicable
[Stage 0:> (0 + 0) / 2]
[Stage 0:> (0 + 1) / 2]
[Stage 0:> (0 + 2) / 2]
Lines with a: 60, Lines with b: 29
I am getting below error Please help me in resolving it.
“C:\Program Files\Java\jdk1.7.0_80\bin\java” -Didea.launcher.port=7549 “-Didea.launcher.bin.path=C:\Program Files (x86)\JetBrains\IntelliJ IDEA Community Edition 14.1.4\bin” -Dfile.encoding=windows-1252 -classpath “C:\Program Files\Java\jdk1.7.0_80\jre\lib\charsets.jar;C:\Program Files\Java\jdk1.7.0_80\jre\lib\deploy.jar;C:\Program Files\Java\jdk1.7.0_80\jre\lib\javaws.jar;C:\Program Files\Java\jdk1.7.0_80\jre\lib\jce.jar;C:\Program Files\Java\jdk1.7.0_80\jre\lib\jfr.jar;C:\Program Files\Java\jdk1.7.0_80\jre\lib\jfxrt.jar;C:\Program Files\Java\jdk1.7.0_80\jre\lib\jsse.jar;C:\Program Files\Java\jdk1.7.0_80\jre\lib\management-agent.jar;C:\Program Files\Java\jdk1.7.0_80\jre\lib\plugin.jar;C:\Program Files\Java\jdk1.7.0_80\jre\lib\resources.jar;C:\Program Files\Java\jdk1.7.0_80\jre\lib\rt.jar;C:\Program Files\Java\jdk1.7.0_80\jre\lib\ext\access-bridge-64.jar;C:\Program Files\Java\jdk1.7.0_80\jre\lib\ext\dnsns.jar;C:\Program Files\Java\jdk1.7.0_80\jre\lib\ext\jaccess.jar;C:\Program Files\Java\jdk1.7.0_80\jre\lib\ext\localedata.jar;C:\Program Files\Java\jdk1.7.0_80\jre\lib\ext\sunec.jar;C:\Program Files\Java\jdk1.7.0_80\jre\lib\ext\sunjce_provider.jar;C:\Program Files\Java\jdk1.7.0_80\jre\lib\ext\sunmscapi.jar;C:\Program Files\Java\jdk1.7.0_80\jre\lib\ext\zipfs.jar;C:\Users\Amrit\IdeaProjects\ScalapProject\out\production\ScalapProject;C:\Program Files (x86)\scala\lib\scala-actors-2.11.0.jar;C:\Program Files (x86)\scala\lib\scala-actors-migration_2.11-1.1.0.jar;C:\Program Files (x86)\scala\lib\scala-library.jar;C:\Program Files (x86)\scala\lib\scala-parser-combinators_2.11-1.0.3.jar;C:\Program Files (x86)\scala\lib\scala-reflect.jar;C:\Program Files (x86)\scala\lib\scala-swing_2.11-1.0.1.jar;C:\Program Files (x86)\scala\lib\scala-xml_2.11-1.0.3.jar;C:\Users\Amrit\Desktop\spark-1.3.1-bin-hadoop2.4\spark-1.3.1-bin-hadoop2.4\lib\spark-assembly-1.3.1-hadoop2.4.0.jar;C:\Program Files (x86)\JetBrains\IntelliJ IDEA Community Edition 14.1.4\lib\idea_rt.jar” com.intellij.rt.execution.application.AppMain HelloWorld
Using Spark’s default log4j profile: org/apache/spark/log4j-defaults.properties
15/08/25 01:09:07 INFO SparkContext: Running Spark version 1.3.1
15/08/25 01:09:13 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
15/08/25 01:09:14 ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:318)
at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:333)
at org.apache.hadoop.util.Shell.(Shell.java:326)
at org.apache.hadoop.util.StringUtils.(StringUtils.java:76)
at org.apache.hadoop.security.Groups.parseStaticMapping(Groups.java:93)
at org.apache.hadoop.security.Groups.(Groups.java:77)
at org.apache.hadoop.security.Groups.getUserToGroupsMappingService(Groups.java:240)
at org.apache.hadoop.security.UserGroupInformation.initialize(UserGroupInformation.java:255)
at org.apache.hadoop.security.UserGroupInformation.ensureInitialized(UserGroupInformation.java:232)
at org.apache.hadoop.security.UserGroupInformation.loginUserFromSubject(UserGroupInformation.java:718)
at org.apache.hadoop.security.UserGroupInformation.getLoginUser(UserGroupInformation.java:703)
at org.apache.hadoop.security.UserGroupInformation.getCurrentUser(UserGroupInformation.java:605)
at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2001)
at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2001)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.util.Utils$.getCurrentUserName(Utils.scala:2001)
at org.apache.spark.SecurityManager.(SecurityManager.scala:207)
at org.apache.spark.SparkEnv$.create(SparkEnv.scala:218)
at org.apache.spark.SparkEnv$.createDriverEnv(SparkEnv.scala:163)
at org.apache.spark.SparkContext.createSparkEnv(SparkContext.scala:269)
at org.apache.spark.SparkContext.(SparkContext.scala:272)
at HelloWorld$.main(HelloWorld.scala:13)
at HelloWorld.main(HelloWorld.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at com.intellij.rt.execution.application.AppMain.main(AppMain.java:140)
15/08/25 01:09:14 INFO SecurityManager: Changing view acls to: Amrit
15/08/25 01:09:14 INFO SecurityManager: Changing modify acls to: Amrit
15/08/25 01:09:14 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(Amrit); users with modify permissions: Set(Amrit)
Exception in thread “main” java.lang.NoSuchMethodError: scala.collection.immutable.HashSet$.empty()Lscala/collection/immutable/HashSet;
at akka.actor.ActorCell$.(ActorCell.scala:336)
at akka.actor.ActorCell$.(ActorCell.scala)
at akka.actor.RootActorPath.$div(ActorPath.scala:159)
at akka.actor.LocalActorRefProvider.(ActorRefProvider.scala:464)
at akka.remote.RemoteActorRefProvider.(RemoteActorRefProvider.scala:124)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:526)
at akka.actor.ReflectiveDynamicAccess$$anonfun$createInstanceFor$2.apply(DynamicAccess.scala:78)
at scala.util.Try$.apply(Try.scala:191)
at akka.actor.ReflectiveDynamicAccess.createInstanceFor(DynamicAccess.scala:73)
at akka.actor.ReflectiveDynamicAccess$$anonfun$createInstanceFor$3.apply(DynamicAccess.scala:84)
at akka.actor.ReflectiveDynamicAccess$$anonfun$createInstanceFor$3.apply(DynamicAccess.scala:84)
at scala.util.Success.flatMap(Try.scala:230)
at akka.actor.ReflectiveDynamicAccess.createInstanceFor(DynamicAccess.scala:84)
at akka.actor.ActorSystemImpl.liftedTree1$1(ActorSystem.scala:584)
at akka.actor.ActorSystemImpl.(ActorSystem.scala:577)
at akka.actor.ActorSystem$.apply(ActorSystem.scala:141)
at akka.actor.ActorSystem$.apply(ActorSystem.scala:118)
at org.apache.spark.util.AkkaUtils$.org$apache$spark$util$AkkaUtils$$doCreateActorSystem(AkkaUtils.scala:122)
at org.apache.spark.util.AkkaUtils$$anonfun$1.apply(AkkaUtils.scala:55)
at org.apache.spark.util.AkkaUtils$$anonfun$1.apply(AkkaUtils.scala:54)
at org.apache.spark.util.Utils$$anonfun$startServiceOnPort$1.apply$mcVI$sp(Utils.scala:1837)
at scala.collection.immutable.Range.foreach$mVc$sp(Range.scala:166)
at org.apache.spark.util.Utils$.startServiceOnPort(Utils.scala:1828)
at org.apache.spark.util.AkkaUtils$.createActorSystem(AkkaUtils.scala:57)
at org.apache.spark.SparkEnv$.create(SparkEnv.scala:223)
at org.apache.spark.SparkEnv$.createDriverEnv(SparkEnv.scala:163)
at org.apache.spark.SparkContext.createSparkEnv(SparkContext.scala:269)
at org.apache.spark.SparkContext.(SparkContext.scala:272)
at HelloWorld$.main(HelloWorld.scala:13)
at HelloWorld.main(HelloWorld.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at com.intellij.rt.execution.application.AppMain.main(AppMain.java:140)
Process finished with exit code 1
“15/08/25 01:09:14 ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.”. Please double-check your winutils position.
hi, i got a WARN as follow, how should i fix it? thanks.
16/01/30 14:41:19 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
Maybe http://stackoverflow.com/questions/30369380/hadoop-unable-to-load-native-hadoop-library-for-your-platform-error-on-docker can help you!
Thanks, my colleague reminds me that my mistake is scala version, as you wrote at the beginning of your blog . After i change scala 2.11 to scala 2.10, anything is ok .
————————————————————————————————————–
Firstly, you should install Scala 2.10.x version on Windows to run Spark, else you would get errors like this:
Exception in thread “main” java.lang.NoSuchMethodError: scala.collection.immutable.HashSet$.empty()Lscala/collection/immutable/HashSet;
at akka.actor.ActorCell$.(ActorCell.scala:305)
at akka.actor.ActorCell$.(ActorCell.scala)
at akka.actor.RootActorPath.$div(ActorPath.scala:152)
……
hi, i want to compute on Aliyun,not on my local machine, do you know how to do it?
I don’t have Aliyun environment, so what is the problem now?
i am a R user, Rstudio provide a sever version, so i can use Aliyun as computation platform and don`t set any configuration to my computer . i want to do similar things, i write scripts of spark using IntelliJ IDEA at my poor computer and execute them at Aliyun. my colleague said that now it isn`t possible to realise.
do you have any idea?
Per my understanding, you should make a connection between Aliyun and your computer, that is after writing script, the intellij or other programs can upload it to Aliyun, and execute it. Sorry for I haven’t done the similar work before, but I think you can try to ask help from intellij community or stackoverflow. Hope this helpful!
Thanks ,Helped me a lot
hello, seems like a useful tutorial, but following your indications and going through the just downloaded spark directory (like there: https://github.com/apache/spark), there is no “spark-assembly-x.x.x-hadoopx.x.x.jar” you are talking about…
Where can I find it ?
I thinkd you can download spark from http://spark.apache.org/downloads.html.
There’s a lot to know about this, but you have made nice points.