I used an old machine (the OS is Arch Linux, and memory less than 3G) to build stxxl project:
# cmake -DBUILD_TESTS=ON ..
-- The C compiler identification is GNU 7.3.0
-- The CXX compiler identification is GNU 7.3.0
......
# make VERBOSE=1
......
cd /root/stxxl/build/examples/applications && /usr/bin/c++ -D_FILE_OFFSET_BITS=64 -D_LARGEFILE_SOURCE -D_LARGE_FILES -I/root/stxxl/include -I/root/stxxl/build/include -W -Wall -pedantic -Wno-long-long -Wextra -ftemplate-depth=1024 -std=c++11 -fopenmp -g -o CMakeFiles/skew3-lcp.dir/skew3-lcp.cpp.o -c /root/stxxl/examples/applications/skew3-lcp.cpp
The default compiler is gcc 7.3.0, and the building process was stuck at compiling skew3-lcp.cpp. The output of htop showed that nearly all memory is occupied:
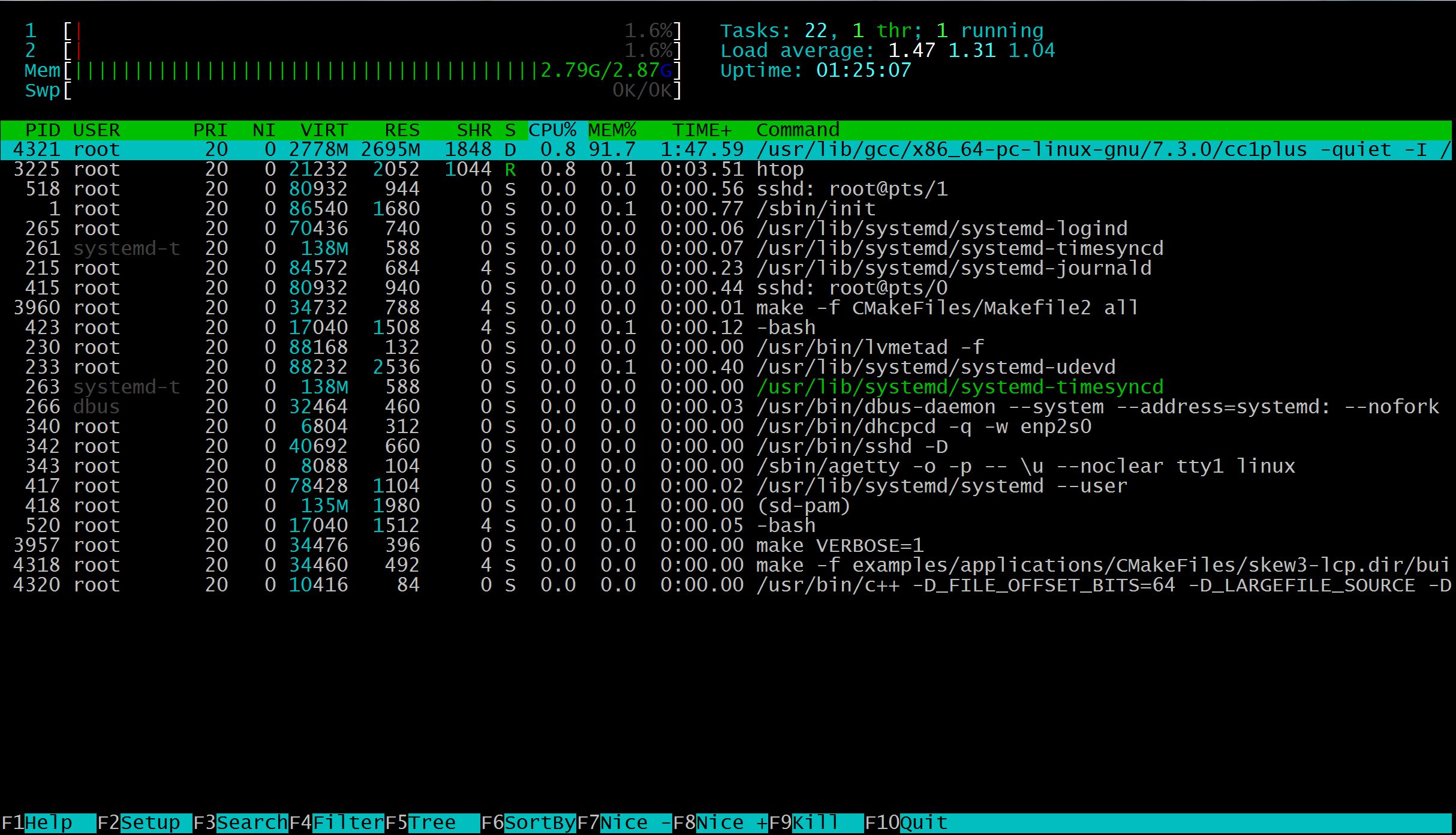
Switch to clang:
# cmake -DCMAKE_C_COMPILER=clang -DCMAKE_CXX_COMPILER=clang++ -DBUILD_TESTS=ON ..
-- The C compiler identification is Clang 5.0.1
-- The CXX compiler identification is Clang 5.0.1
......
# make
......
[100%] Linking CXX executable test1
[100%] Built target test1
The project can be built successfully, and the peak memory used for compiling skew3-lcp.cpp is 1.78G. Based on this test, if you have compiling task which needs much memory, clang may be a better choice than gcc.