I came across a program crash last week:
Program terminated with signal 11, Segmentation fault.
#0 0x00007ffff365bd29 in __memcpy_ssse3_back () from /usr/lib64/libc.so.6
#0 0x00007ffff365bd29 in __memcpy_ssse3_back () from /usr/lib64/libc.so.6
#1 0x00007ffff606025c in memcpy (__len=<optimized out>, __src=0x0, __dest=0x0) at /usr/include/bits/string3.h:51
......
#5 0x0000000000000000 in ?? ()
The 5th stack frame address is 0x0000000000000000, and it seems not right. To debug it, get the registers values first:
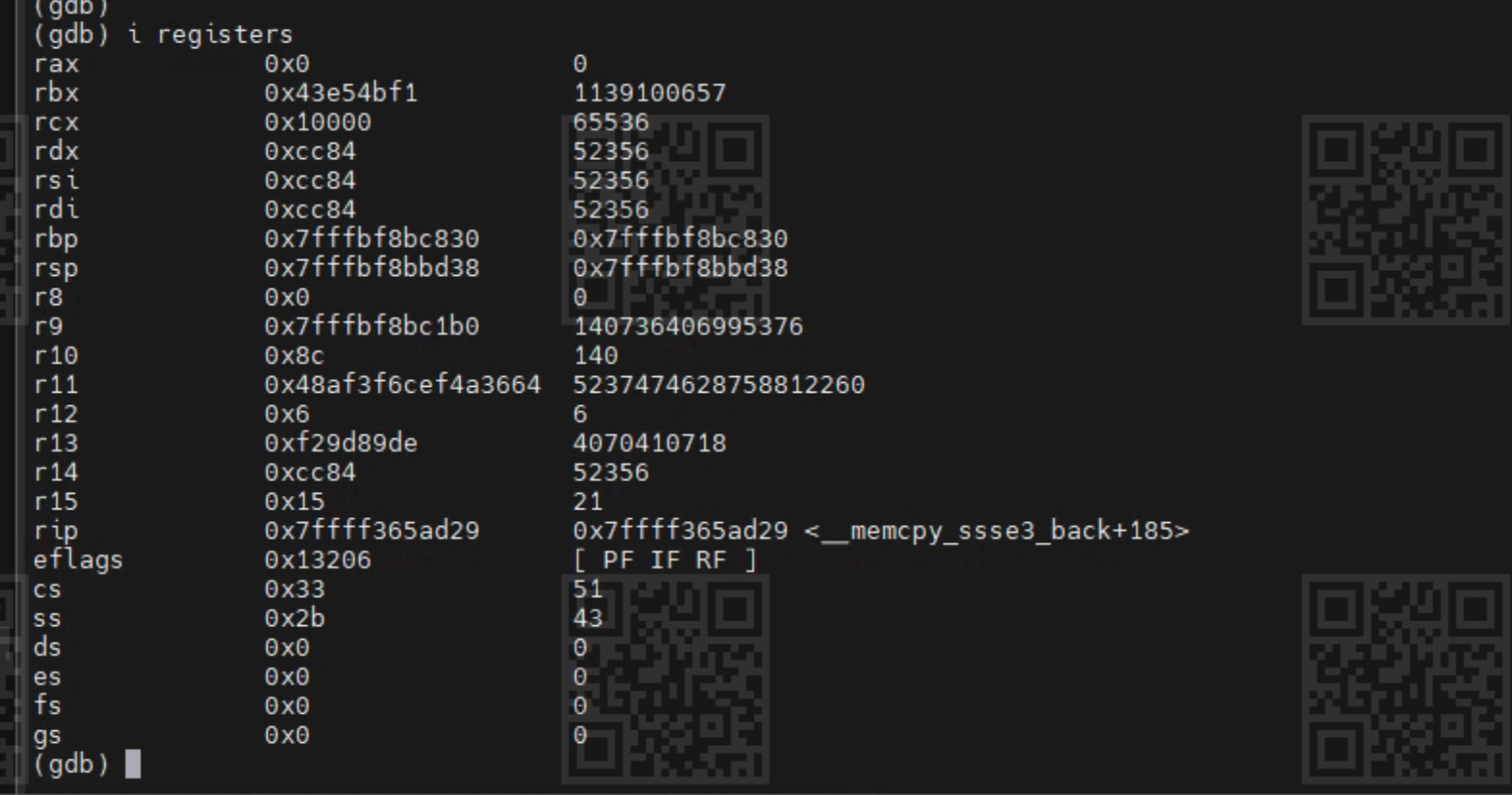
According to X86_64 architecture, The value in memory address (%rbp) should be previous %rbp value, and the value in memory address (%rbp) + 8 should be return address. Checked these two values, and found they are all 0s, so it means the stack is corrupted.
The next thing to do is dump the memory between %rsp and %rbp, and refer the assembly code of the function at the same time. With this, I can know which memory part doesn’t seem correct, and review code accordingly. Finally I found the root cause and fixed it.
P.S., in optimisation build mode, some functions may be inlined, so please be aware of this caveat.