程序员经常会搜索一些特殊符号,比如Scala的=>,ruby的$$等等,一般的搜索网站都会过滤掉这些特殊符号,所以结果不尽如人意。http://symbolhound.com/可以很好地处理这些符号,搜索结果帮助很大,可以考虑试试它!
月度归档: 2015 年 6 月
Scala的“=>”符号简介
Scala中的=>符号可以看做是创建函数实例的语法糖。例如:A => T,A,B => T表示一个函数的输入参数类型是“A”,“A,B”,返回值类型是T。请看下面这个实例:
scala> val f: Int => String = myInt => "The value of myInt is: " + myInt.toString()
f: Int => String = <function1>
scala> println(f(3))
The value of myInt is: 3
上面例子定义函数f:输入参数是整数类型,返回值是字符串。
另外,() => T表示函数输入参数为空,而A => Unit则表示函数没有返回值。
Spark RDD详解
RDD(Resilient Distributed Dataset)是Spark中的核心概念,它表示一个不可变的分布式数据集合。每个RDD被分成不同的部分(partition),这样就可以在集群(cluster)的不同节点(node)上进行并行计算。在Spark中,所有的工作都围绕RDD展开:创建RDD,转换现有的RDD,对RDD进行运算得到计算结果,等等。
创建RDD有两种方式:
a) 在驱动程序中加载对象集合。例如:
val lines = sc.parallelize(List("a", "b", "c"))
这种方式在实际中用的较少,因为它要求把整个数据集加载到一台机器的内存里。
b) 加载外部数据集。例如:
val lines = sc.textFile("/path/to/README.md")
这种方式使用较多。
RDD支持两种形式的运算(operation):“转换”(transformation)和“处理”(action)。
a)转换(transformation)
“转换”是这样一种运算:作用在一个RDD上,返回一个新的RDD(例如:map和filter操作)。“转换” 运算是“Lazy Evaluation”的:Spark不会马上执行运算,直到第一次使用新的RDD才开始。许多“转换” 运算是“element-wise”的,也即一次只操作一个元素(element),但这并不是对所有的“转换”运算都成立。
举个例子:
val inputRDD = sc.textFile("log.txt")
val errorsRDD = inputRDD.filter(line => line.contains("error"))
上面例子找到log.txt文件中包含error字段的行。filter()操作并不会改变已经存在的inputRDD, 而是返回一个指向新的RDD的指针:errorsRDD。
通过“转换”运算可以不断地从现有RDD生成新的RDD,Spark会记录不同RDD之间的依赖性,称之为“谱系图”(lineage graph)。 Spark可以利用这个信息根据需求计算RDD或者恢复丢失的数据。
b) 处理(action)
“处理”运算会返回一个最终的值给驱动程序,或是写一些数据到外部的存储系统。“处理”运算会强制进行在RDD 上的“转换”运算,因为需要得到真正的计算结果。
举个例子:
println("Input had " + errorsRDD.count() + " concerning lines")
上面例子调用count()计算行数。
如果对一个运算是“转换”还是“处理”分不清的话,可以查看它的返回值。“转换”运算返回RDD类型,而“处理”运算返回其它类型。
持久化(Persistence,Caching)
默认情况下,每次对RDD进行“处理”(action)运算时,Spark都会对RDD进行重新计算。为了避免每次都重新计算,可以对RDD进行持久化操作(调用RDD.persist())。第一次运算后,Spark会把RDD内容存在内存里(分布在集群的不同机器),以便将来复用。
总结一下,每个Spark程序或Spark shell会话工作流程如下:
a) 从外部数据创建输入RDD;
b) 使用“转换”(transformation)运算从输入RDD生成新的RDD;
c) 对需要重复使用的RDD进行持久化操作;
d) 对RDD进行并行运算。
参考资料:
《Learning Spark》。
Go语言的new函数
Go语言有一个内置的new函数,其定义如下:
func new
func new(Type) *Type
The new built-in function allocates memory. The first argument is a type, not a value, and the value returned is a pointer to a newly allocated zero value of that type.
其输入参数是一个类型,返回是一个指向该类型内存的指针,且指针所指向的这块内存已被初始化为该类型的0值。下面例子演示了如何使用new函数:
package main
import (
"fmt"
)
func main() {
v := new(int)
*v++
fmt.Println(*v)
}
运行结果如下:
1
new函数的出现早于make和&{},并且它可以让人直观地认识到返回值就是一个指针,在某些情形下,这会让人更清晰地理解代码。
参考资料:
(1)http://golang.org/pkg/builtin/#new;
(2)Why is there a “new” in Go?。
Goroutine浅析
Goroutine是Go语言并发编程中的一个重要概念,事实上我们可以把它理解成为非常轻量级的线程(thread)或协程(coroutine)。每个运行的 Go程序都至少包含一个goroutine——运行main函数的goroutine。
创建goroutine要使用go语句:
go function(arguments)
go func(parameters) { block } (arguments)
go后面要跟一个已经定义的函数或是一个现定义的匿名函数。执行完这条语句后,就会启动一个独立的,和其它程序中已有的goroutine并行运行的新的goroutine。
runtime程序包中提供了一个GOMAXPROCS函数,它可以用来设定实际上有多少个操作系统线程来执行Go程序。截止到目前为止(1.4.2版本),这个值一直默认为1。从1.5版本起,Go的开发者打算把这个默认值改为可以使用的CPU个数,并认为这会改善Go程序的性能。看一个简单的程序:
package main
import (
"fmt"
"time"
"runtime"
)
func sleep(s string) {
for {
fmt.Println(s)
time.Sleep(time.Second)
}
}
func main() {
fmt.Println(runtime.GOMAXPROCS(0))
go sleep("Hello")
go sleep("World")
time.Sleep(1000 * time.Second)
}
main函数第一行打印了当前系统默认设置的GOMAXPROCS的值。另外在main goroutine里启动了两个goroutine,分别交替地打印“Hello”和“World”。执行如下:
1
Hello
World
Hello
World
Hello
World
Hello
World
......
可以看到默认的GOMAXPROCS的值的确为1。“Hello”和“World”也被交替打印了。在执行过程中,使用pstack命令查看进程的线程调用栈:
[root@Fedora ~]# pstack 10773
Thread 1 (LWP 10773):
#0 runtime.futex () at /usr/local/go/src/runtime/sys_linux_amd64.s:278
#1 0x000000000042b197 in runtime.futexsleep () at /usr/local/go/src/runtime/os_linux.c:49
#2 0x000000000040adae in runtime.notesleep (n=0x54df18 <runtime.m0+216>) at /usr/local/go/src/runtime/lock_futex.go:145
#3 0x000000000042e669 in stopm () at /usr/local/go/src/runtime/proc.c:1178
#4 0x000000000042f4c2 in findrunnable () at /usr/local/go/src/runtime/proc.c:1487
#5 0x000000000042f881 in schedule () at /usr/local/go/src/runtime/proc.c:1575
#6 0x000000000042fb03 in runtime.park_m () at /usr/local/go/src/runtime/proc.c:1654
#7 0x000000000041f94a in runtime.mcall () at /usr/local/go/src/runtime/asm_amd64.s:186
#8 0x000000000054dab0 in runtime.g0 ()
#9 0x000000000042de04 in runtime.mstart () at /usr/local/go/src/runtime/proc.c:836
#10 0x000000000041f84c in runtime.rt0_go () at /usr/local/go/src/runtime/asm_amd64.s:106
#11 0x0000000000000001 in ?? ()
#12 0x00007ffd43803348 in ?? ()
#13 0x0000000000000001 in ?? ()
#14 0x00007ffd43803348 in ?? ()
#15 0x0000000000000000 in ?? ()
可以看到的确只有一个线程在运行。
Goroutine的调度器(scheduler)并不是完全抢占的(fully-preemptive),当有GOMAXPROCS个goroutine并行运行时,运行的goroutine必须要放弃执行权,其它goroutine才有机会得到运行(比方说,调用time.Sleep())。此外,取决于调度器的实现,goroutine可能在执行任何函数时,都会放弃CPU。看下面这个程序:
package main
import (
"fmt"
)
func say(s string) {
for i := 0; i < 5; i++ {
fmt.Println(s)
}
}
func main() {
go say("world")
say("hello")
}
执行结果如下:
hello
hello
hello
hello
hello
main goroutine运行起来以后,并没有给另外一个goroutine打印“world”的机会。随着main goroutine执行完毕,这个程序也退出了。修改程序如下:
package main
import (
"fmt"
"time"
)
func say(s string) {
for i := 0; i < 5; i++ {
fmt.Println(s)
}
}
func main() {
go say("world")
say("hello")
time.Sleep(time.Second)
}
这次执行结果如下:
hello
hello
hello
hello
hello
world
world
world
world
world
在main函数最后加了一行time.Sleep(time.Second),这样main goroutine就可以把CPU的执行权让出来,所以另外一个goroutine得以运行。
参考资料:
(1)Go 1.5 GOMAXPROCS Default;
(2)Some questions about goroutine;
(3)Why is time.sleep required to run certain goroutines。
Spark应用浅析
每个Spark应用(application)都包含一个用来在集群(cluster)上启动各种并行操作的驱动程序(driver program)。驱动程序不仅包含了Spark应用的main函数,还定义了集群上的分布式数据集(distributed dataset),而且会对这些数据集进行各种操作。在你使用Spark Shell进行交互操作时:
[root@Fedora bin]# ./spark-shell
scala> sc.parallelize(1 to 1000).count()
res0: Long = 1000
Spark Shell自身就是驱动程序。
驱动程序通过一个SparkContext对象来访问Spark,这个对象代表一个针对计算集群(computing cluster)的连接。Spark Shell会自动产生一个叫sc的SparkContext对象,所以在上面的例子中可以直接使用sc。在Spark Shell中输入sc,可以看到它的类型信息:
scala> sc
res0: org.apache.spark.SparkContext = org.apache.spark.SparkContext@45707f76
有了SparkContext对象之后,就可以用它来产生数据集,然后在数据集上进行各种操作。而为了进行这些操作,驱动程序要管理一群被称作“executor”的节点(node)。下图描述了Spark如何在集群上执行任务:
参考资料:
《Learning Spark》。
Spark结构初探
Apache Spark(以下简称Spark)是一个快速的,通用的集群计算平台(Apache Spark is a cluster computing platform designed to be fast and general-purpose),它由多个紧密结合的构件组成:
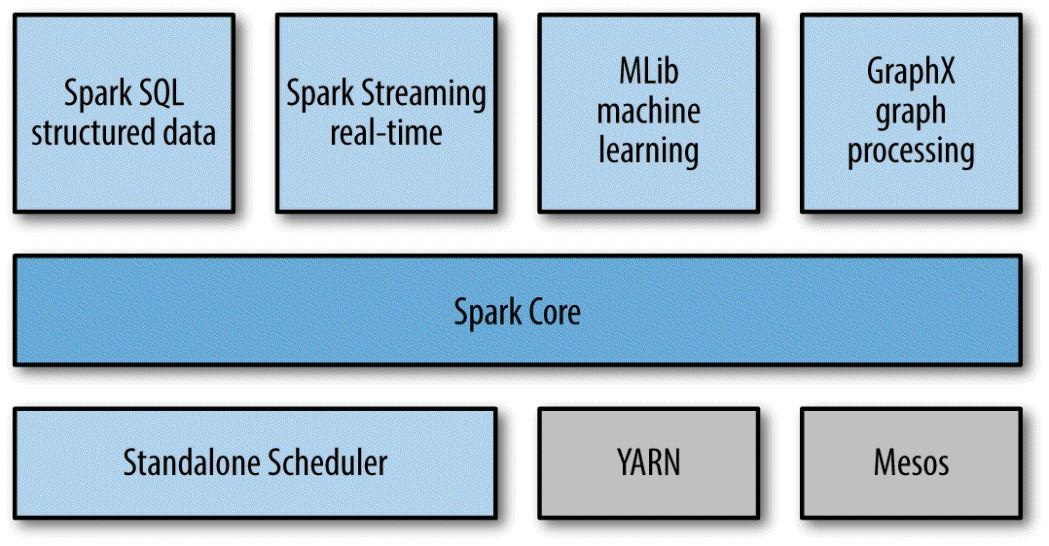
Spark Core包含Spark的最基本的功能:任务调度,内存管理,故障恢复,存储系统的交互,等等。
Spark SQL是用来处理结构化数据的程序包。它不仅允许使用SQL,HQL(Hive Query Language)来查询数据,并且支持多种数据源:Hive tables,Parquet和JSON。
Spark Streaming用来处理实时的数据流。
MLib是一个提供了很多机器学习算法的库。
GraphX是一个提供操作图表以及对图表进行并行计算的库。
Spark除了自带了一个简单的Cluster Manager:Standalone Scheduler以外,也支持Hadoop YARN和Apache Mesos。
Spark可以把存储在Hadoop Distributed File System(HDFS)或其它支持Hadoop API的存储系统(包含你本地文件系统,Amazon S3,Cassandra,Hive,HBase等)上的文件转化成分布式数据集(distributed datasets)。要注意,Hadoop对于Spark来说不是必不可少的,只要存储系统实现Hadoop API即可。
参考资料:
《Learning Spark》。
什么是JIT compiler?
JIT(Just-In-Time)Compiler是在程序开始运行以后,在执行过程中把代码(通常是字节码或虚拟机指令)转化成另外一种运行更快的指令,通常就是程序所在机器的CPU指令集。与之相比,传统的编译器则会在程序运行之前就把所有代码编译成机器指令。
Go语言“:=”用法浅析
Go语言中可以使用“:=”为一个新的变量完成声明以及初始化的工作,如下例所示:
i := 1
等价于:
var i = 1
要注意语句中没有变量类型,不是var i int = 1。
“:=”不能重新声明一个已经声明过的变量,如下例所示:
package main
import "fmt"
func main() {
var i = 1
i := 2
fmt.Println(i)
}
编译结果:
C:/Go\bin\go.exe run C:/Work/go_work/Hello.go
# command-line-arguments
.\Hello.go:8: no new variables on left side of :=
错误的原因是变量被重复声明了。
但使用“:=”为多个变量赋值时,如果引入了至少一个新的变量,编译是可以通过的,如下例所示:
package main
import "fmt"
func main() {
var i = 1
i, err := 2, false
fmt.Println(i, err)
}
编译执行:
C:/Go\bin\go.exe run C:/Work/go_work/Hello.go
2 false
要注意这个时候,并没有重新声明“i”变量,只是为之前声明的“i”变量赋值。
“:=”只能用在函数体中。它的一个重要用途是用在“if”,“for”和“switch”语句的初始化,使变量成为一个“临时变量”,也就是变量的作用域仅限于这条语句。如下例所示:
package main
import "fmt"
func main() {
for j := 3; j <= 5; j++ {
fmt.Println(j)
}
fmt.Println(j)
}
编译结果:
C:/Go\bin\go.exe run C:/Work/go_work/Hello.go
# command-line-arguments
.\Hello.go:11: undefined: j
“j”的声明作用域仅限于“for”语句,所以编译第二个打印语句会出错。
参考资料:
(1)Short variable declarations;
(2)Assignment operator in Go language。
GOROOT和GOPATH
GOROOT指向Go开发包的安装目录。从Go 1.0开始,不必显示地设置GOROOT环境变量。Windows安装包将会自动设置GOROOT,默认装在C:\Go:
GOROOT=C:\Go\
而在*nix环境下,下载Go安装包并解压在/usr/local/目录下,然后把/usr/local/go/bin加入PATH环境变量即可:
export PATH=$PATH:/usr/local/go/bin
如果Go安装包没有安装在默认的目录下(Windows为C:\Go,*nix为/usr/local/go),则需要手动设置GOROOT,举个例子(*nix):
export GOROOT=$HOME/go
GOPATH指定了Go工程目录,包含src,pkg和bin三个子目录。这是开发Go程序时,唯一需要显示设置的环境变量。当使用go get目录下载Go第三方程序包时,也会安装在这个目录下。此外,为了方便,要记得把$GOPATH/bin也加到PATH环境变量:
export PATH=$PATH:$GOPATH/bin
另外,根据这个帖子的推荐,设置一个GoPATH足够了。
参考资料:
1. Easy Go Programming Setup for Windows;
2. You don’t need to set GOROOT, really;
3. How to Write Go Code;
4. Go Getting Started。