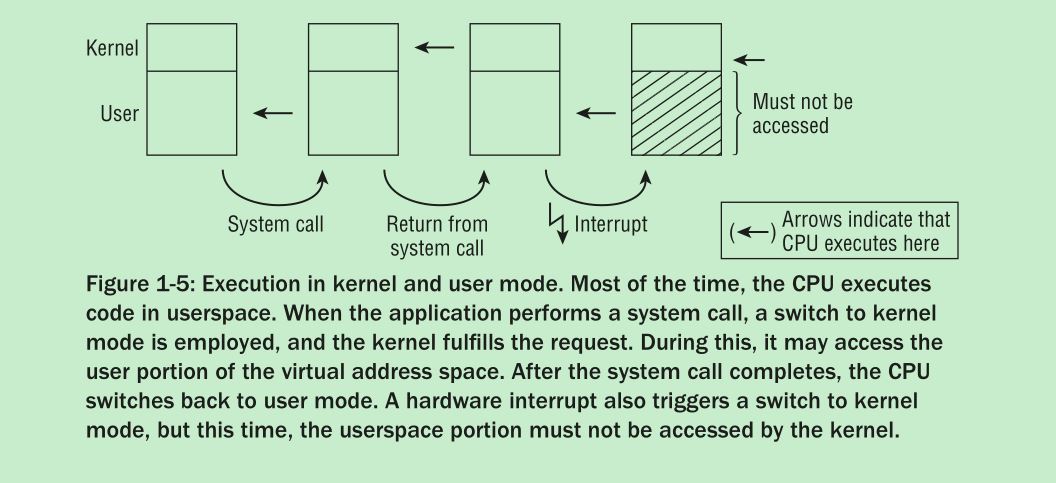
SystemTap追踪user-space程序时需要安装user-space程序的debug-info包。举个例子:
# stap -d /bin/ls --ldd -e 'probe process("ls").function("xmalloc") {print_usyms(ubacktrace())}' -c "ls /"
semantic error: while resolving probe point: identifier 'process' at <input>:1:7
source: probe process("ls").function("xmalloc") {print_usyms(ubacktrace())}
^
semantic error: no match (similar functions: malloc, calloc, realloc, close, mbrtowc)
Pass 2: analysis failed. [man error::pass2]
安装coreutils-debuginfo包:
# zypper in coreutils-debuginfo
Loading repository data...
Reading installed packages...
Resolving package dependencies...
The following NEW package is going to be installed:
coreutils-debuginfo
The following package is not supported by its vendor:
coreutils-debuginfo
1 new package to install.
Overall download size: 2.1 MiB. Already cached: 0 B. After the operation, additional 18.6 MiB will be used.
Continue? [y/n/? shows all options] (y): y
Retrieving package coreutils-debuginfo-8.22-9.1.x86_64 (1/1), 2.1 MiB ( 18.6 MiB unpacked)
Retrieving: coreutils-debuginfo-8.22-9.1.x86_64.rpm ...................................................................[done (105.3 KiB/s)]
Checking for file conflicts: ........................................................................................................[done]
(1/1) Installing: coreutils-debuginfo-8.22-9.1 ......................................................................................[done]
再次执行上述命令:
# stap -d /bin/ls --ldd -e 'probe process("ls").function("xmalloc") {print_usyms(ubacktrace())}' -c "ls /"
bin boot dev etc home lib lib64 lost+found mnt opt proc root run sbin selinux srv sys tmp usr var
0x4114a0 : xmalloc+0x0/0x20 [/usr/bin/ls]
0x411674 : xmemdup+0x14/0x30 [/usr/bin/ls]
0x40ee4a : clone_quoting_options+0x2a/0x40 [/usr/bin/ls]
0x403828 : main+0xa58/0x2140 [/usr/bin/ls]
0x7fad37eefb05 : __libc_start_main+0xf5/0x1c0 [/lib64/libc-2.19.so]
0x404f39 : _start+0x29/0x30 [/usr/bin/ls]
0x4114a0 : xmalloc+0x0/0x20 [/usr/bin/ls]
0x411674 : xmemdup+0x14/0x30 [/usr/bin/ls]
0x40ee4a : clone_quoting_options+0x2a/0x40 [/usr/bin/ls]
0x403887 : main+0xab7/0x2140 [/usr/bin/ls]
0x7fad37eefb05 : __libc_start_main+0xf5/0x1c0 [/lib64/libc-2.19.so]
0x404f39 : _start+0x29/0x30 [/usr/bin/ls]
0x4114a0 : xmalloc+0x0/0x20 [/usr/bin/ls]
0x4039e4 : main+0xc14/0x2140 [/usr/bin/ls]
0x7fad37eefb05 : __libc_start_main+0xf5/0x1c0 [/lib64/libc-2.19.so]
.....