
月度归档: 2016 年 12 月
CUDA编程笔记(8)——CUDA kernel
这篇笔记摘自Professional CUDA C Programming:
A CUDA kernel call is a direct extension to the C function syntax that adds a kernel’s execution confguration inside triple-angle-brackets:
kernel_name <<<grid, block>>>(argument list);
As explained in the previous section, the CUDA programming model exposes the thread hierarchy. With the execution configuration, you can specify how the threads will be scheduled to run on the GPU. The first value in the execution configuration is the grid dimension, the number of blocks to launch. The second value is the block dimension, the number of threads within each block. By specifying the grid and block dimensions, you configure:
➤ The total number of threads for a kernel
➤ The layout of the threads you want to employ for a kernel
在kernel_name <<<grid, block>>>(argument list);中,grid参数指定block数量,而block参数指定每个block中thread数量,二者之积就是grid一共拥有的thread数量。
Unlike a C function call, all CUDA kernel launches are asynchronous. Control returns to the CPU immediately after the CUDA kernel is invoked.
A kernel function is the code to be executed on the device side. In a kernel function, you define the computation for a single thread, and the data access for that thread. When the kernel is called, many different CUDA threads perform the same computation in parallel.
The following restrictions apply for all kernels:
➤ Access to device memory only
➤ Must have void return type
➤ No support for a variable number of arguments
➤ No support for static variables
➤ No support for function pointers
➤ Exhibit an asynchronous behavior
CUDA编程笔记(7)——thread hierarchy
这篇笔记摘自Professional CUDA C Programming:
When a kernel function is launched from the host side, execution is moved to a device where a large number of threads are generated and each thread executes the statements specified by the kernel function. CUDA exposes a thread hierarchy abstraction to enable you to organize your threads. This is a two-level thread hierarchy decomposed into blocks of threads and grids of blocks:
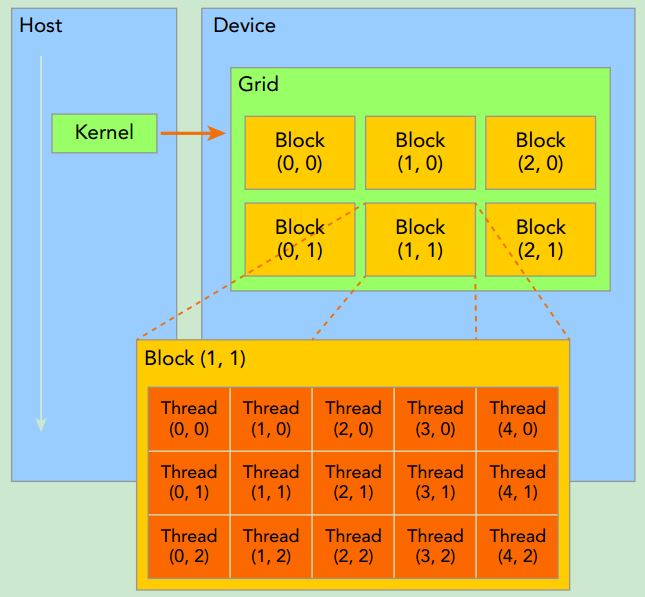
All threads spawned by a single kernel launch are collectively called a grid. All threads in a grid share the same global memory space. A grid is made up of many thread blocks. A thread block is a group of threads that can cooperate with each other using:
➤ Block-local synchronization
➤ Block-local shared memory
Threads from different blocks cannot cooperate.
Threads rely on the following two unique coordinates to distinguish themselves from each other:
➤ blockIdx (block index within a grid)
➤ threadIdx (thread index within a block)
These variables appear as built-in, pre-initialized variables that can be accessed within kernel functions. When a kernel function is executed, the coordinate variables blockIdx and threadIdx are assigned to each thread by the CUDA runtime. Based on the coordinates, you can assign portions of data to different threads. The coordinate variable is of type uint3, a CUDA built-in vector type, derived from the basic integer type.CUDA organizes grids and blocks in three dimensions. The dimensions of a grid and a block are specifed by the following two built-in variables:
➤ blockDim (block dimension, measured in threads)
➤ gridDim (grid dimension, measured in blocks)
These variables are of type dim3, an integer vector type based on uint3 that is used to specify dimensions. When defining a variable of type dim3, any component left unspecified is initialized to 1.
blockIdx&threadIdx是uint3类型,含义是坐标,所以下标从0开始;blockDim&gridDim是dim3类型,含义是维度,即用来计算block中有多少个thread,当前grid中包含多少个block,因此默认值是1。
There are two distinct sets of grid and block variables in a CUDA program: manually-defined dim3 data type and pre-defined uint3 data type. On the host side, you define the dimensions of a grid and block using a dim3 data type as part of a kernel invocation. When the kernel is executing, the CUDA runtime generates the corresponding built-in, pre-initialized grid, block, and thread variables, which are accessible within the kernel function and have type uint3. The manually-defined grid and block variables for the dim3 data type are only visible on the host side, and the built-in, pre-initialized grid and block variables of the uint3 data type are only visible on the device side.
It is important to distinguish between the host and device access of grid and block variables. For example, using a variable declared as block from the host, you define the coordinates and access them as follows:
block.x, block.y, and block.z
On the device side, you have pre-initialized, built-in block size variable available as:
blockDim.x, blockDim.y, and blockDim.z
In summary, you define variables for grid and block on the host before launching a kernel, and access them there with the x, y and z fields of the vector structure from the host side. When the kernel is launched, you can use the pre-initialized, built-in variables within the kernel.下面这
3页摘自Learn CUDA In An Afternoon:



CUDA编程笔记(6)——RUNTIME API VS DRIVER API
这篇笔记摘自Professional CUDA C Programming:
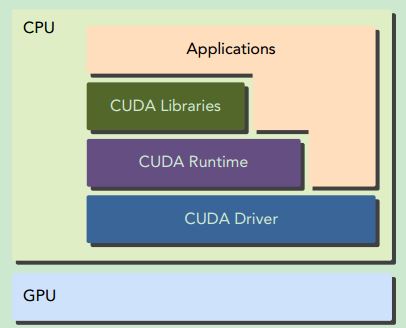
CUDA provides two API levels for managing the GPU device and organizing threads:
➤ CUDA Driver API
➤ CUDA Runtime API
The driver API is a low-level API and is relatively hard to program, but it provides more control over how the GPU device is used. The runtime API is a higher-level API implemented on top of the driver API. Each function of the runtime API is broken down into more basic operations issued to the driver API.There is no noticeable performance difference between the runtime and driver APIs. How your kernels use memory and how you organize your threads on the device have a much more pronounced effect.
These two APIs are mutually exclusive. You must use one or the other, but it is not possible to mix function calls from both.
CUDA编程笔记(5)——CUDA程序结构
这篇笔记摘自Professional CUDA C Programming:
A typical CUDA program structure consists of five main steps:
1. Allocate GPU memories.
2. Copy data from CPU memory to GPU memory.
3. Invoke the CUDA kernel to perform program-specific computation.
4. Copy data back from GPU memory to CPU memory.
5. Destroy GPU memories.CUDA exposes you to the concepts of both memory hierarchy and thread hierarchy, extending your ability to control thread execution and scheduling to a greater degree, using:
➤ Memory hierarchy structure
➤ Thread hierarchy structure
For example, a special memory, called shared memory, is exposed by the CUDA programming model. Shared memory can be thought of as a software-managed cache, which provides great speedup by conserving bandwidth to main memory. With shared memory, you can control the locality of your code directly.When writing a parallel program in ANSI C, you need to explicitly organize your threads with either pthreads or OpenMP, two well-known techniques to support parallel programming on most processor architectures and operating systems. When writing a program in CUDA C, you actually just write a piece of serial code to be called by only one thread. The GPU takes this kernel and makes it parallel by launching thousands of threads, all performing that same computation. The CUDA programming model provides you with a way to organize your threads hierarchically. Manipulating this organization directly affects the order in which threads are executed on the GPU. Because CUDA C is an extension of C, it is often straightforward to port C programs to CUDA C. Conceptually, peeling off the loops of your code yields the kernel code for a CUDA C implementation.
CUDA abstracts away the hardware details and does not require applications to be mapped to traditional graphics APIs. At its core are three key abstractions: a hierarchy of thread groups, a hierarchy of memory groups, and barrier synchronization, which are exposed to you as a minimal set of language extensions.
CUDA编程笔记(4)——CPU THREAD VS GPU THREAD
这篇笔记摘自Professional CUDA C Programming:
Threads on a CPU are generally heavyweight entities. The operating system must swap threads on and off CPU execution channels to provide multithreading capability. Context switches are slow and expensive.
Threads on GPUs are extremely lightweight. In a typical system, thousands of threads are queued up for work. If the GPU must wait on one group of threads, it simply begins executing work on another.
CPU cores are designed to minimize latency for one or two threads at a time, whereas GPU cores are designed to handle a large number of concurrent, lightweight threads in order to maximize throughput.
Today, a CPU with four quad core processors can run only 16 threads concurrently, or 32 if the CPUs support hyper-threading.
Modern NVIDIA GPUs can support up to 1,536 active threads concurrently per multiprocessor. On GPUs with 16 multiprocessors, this leads to more than 24,000 concurrently active threads.
CUDA编程笔记(3)——Heterogeneous architecture
这篇笔记摘自Professional CUDA C Programming:
A typical heterogeneous compute node nowadays consists of two multicore CPU sockets and two or more many-core GPUs. A GPU is currently not a standalone platform but a co-processor to a CPU. Therefore, GPUs must operate in conjunction with a CPU-based host through a PCI-Express bus. That is why, in GPU computing terms, the CPU is called the host and the GPU is called the device.
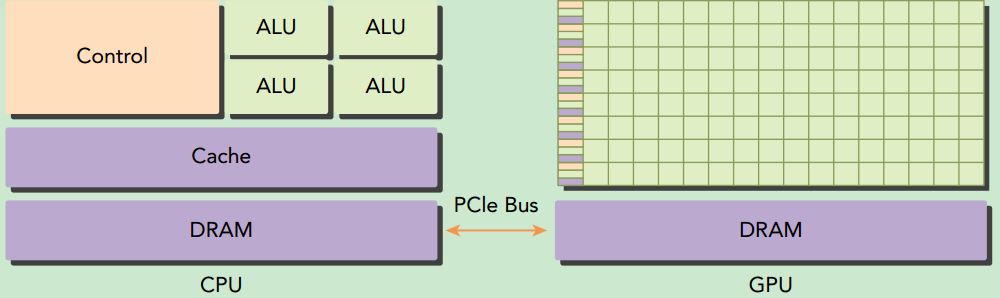
A heterogeneous application consists of two parts:
➤ Host code
➤ Device code
Host code runs on CPUs and device code runs on GPUs. An application executing on a heterogeneous platform is typically initialized by the CPU. The CPU code is responsible for managing the environment, code, and data for the device before loading compute-intensive tasks on the device.There are two important features that describe GPU capability:
➤ Number of CUDA cores
➤ Memory size
Accordingly, there are two different metrics for describing GPU performance:
➤ Peak computational performance
➤ Memory bandwidth
Peak computational performance is a measure of computational capability, usually defined as how many single-precision or double-precision floating point calculations can be processed per second. Peak performance is usually expressed in gflops (billion floating-point operations per second) or tflops (trillion floating-point calculations per second). Memory bandwidth is a measure of the ratio at which data can be read from or stored to memory. Memory bandwidth is usually expressed in gigabytes per second, GB/s.
CUDA编程笔记(2)——GPU core VS CPU core
这篇笔记摘自Professional CUDA C Programming:
Even though many-core and multicore are used to label GPU and CPU architectures, a GPU core is quite different than a CPU core.
A CPU core, relatively heavy-weight, is designed for very complex control logic, seeking to optimize the execution of sequential programs.
A GPU core, relatively light-weight, is optimized for data-parallel tasks with simpler control logic, focusing on the throughput of parallel programs.
CUDA编程笔记(1)——Parallelism
这篇笔记摘自Professional CUDA C Programming:
There are two fundamental types of parallelism in applications:
➤ Task parallelism
➤ Data parallelism
Task parallelism arises when there are many tasks or functions that can be operated independently and largely in parallel. Task parallelism focuses on distributing functions across multiple cores.Data parallelism arises when there are many data items that can be operated on at the same time. Data parallelism focuses on distributing the data across multiple cores.
CUDA programming is especially well-suited to address problems that can be expressed as data parallel computations. Many applications that process large data sets can use a data-parallel model to speed up the computations. Data-parallel processing maps data elements to parallel threads.
There are two basic approaches to partitioning data:
➤ Block: Each thread takes one portion of the data, usually an equal portion of the data.
➤ Cyclic: Each thread takes more than one portion of the data.
简而言之,block就是按线程数等分数据,10个线程就把数据分成10份,一个线程处理一份;而cyclic则是数据的份数大于线程数,举个例子,10个线程把数据分成20份,第一个线程处理第1,11份,第二个线程处理第2,12份。。。。。。,循环处理多次。