如果要编译安装debug版本的程序,可以使用下面命令:
# GO_GCFLAGS='-gcflags "-N -l"' make install
如果要编译安装debug版本的程序,可以使用下面命令:
# GO_GCFLAGS='-gcflags "-N -l"' make install
下面内容选自 FreeBSD Device Drivers:
A device driver can be either statically compiled into the system or dynamically loaded using a loadable kernel module (KLD).
NOTE: Most operating systems call a loadable kernel module an LKM—FreeBSD just had to be different.
A KLD is a kernel subsystem that can be loaded, unloaded, started, and stopped after bootup. In other words, a KLD can add functionality to the kernel and later remove said functionality while the system is running. Needless to say, our “functionality” will be device drivers.
In general, two components are common to all KLDs:
A module event handler
A DECLARE_MODULE macro call
Swarmkit是Docker公司新开源的一个项目,它用来创建和管理cluster。默认情况下使用Docker container来运行任务,但不限于此。
Cluster中的node分成两种:manager和worker。Manager node负责接收用户指令和管理cluster;worker node则是通过executor执行task(默认executor即为Docker container)。Task可以组织成Service。此外,一组manager通过Raft协议形成一个组,并会选出一个leader。只有leader处理所有的请求,其它的成员只是把请求传给leader。
Swarmkit提供了两个可执行程序:swarmd和swarmctl。swarmd用来部署在cluster中的每一个node上,彼此间互相通信,组成cluster;而swarmctl则用来向整个cluster“发号施令”。 下图可以更清楚地描述Swarmkit的内部机制(图片出处:https://pbs.twimg.com/media/Ckb8EMLVAAQrxYH.jpg):
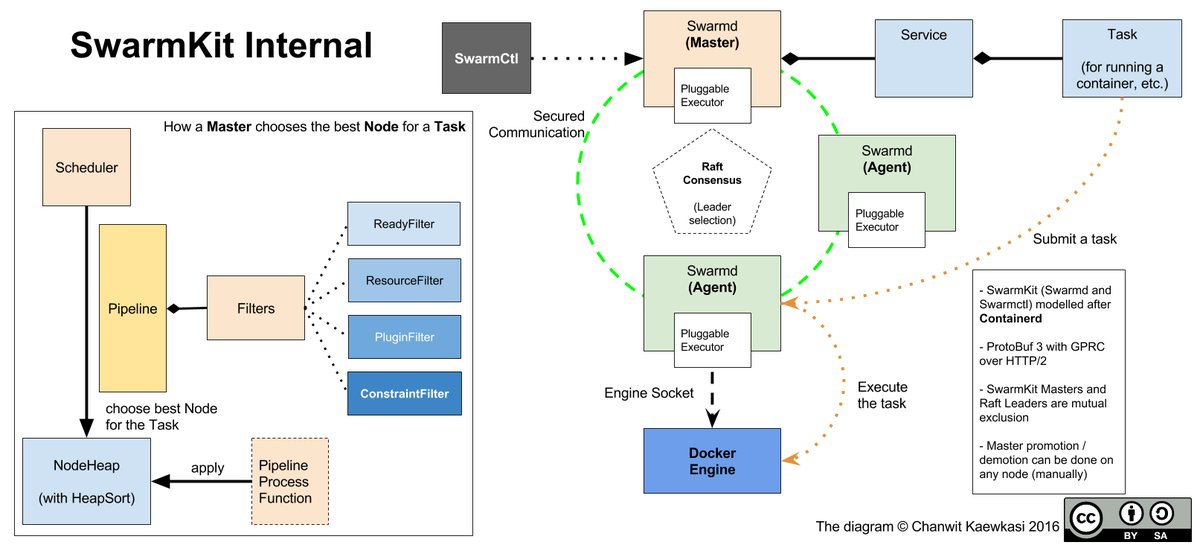
参考资料:
docker-swarmkit;
docker 1.12集成了docker swarm功能。根据Docker Swarm Is Dead. Long Live Docker Swarm.这篇文章,对比docker swarm,docker 1.12有以下优点:
(1)
With swarm mode you create a swarm with the ‘init’ command, and add workers to the cluster with the ‘join’ command. The commands to create and join a swarm literally take a second or two to complete. Mouat said “Comparing getting a Kubernetes or Mesos cluster running, Docker Swarm is a snap”.
Communication between nodes on the swarm is all secured with Transport Layer Security (TLS). For simple setups, Docker 1.12 generates self-signed certificates to use when you create the swarm, or you can provide certificates from your own certificate authority. Those certificates are only used internally by the nodes; any services you publicly expose use your own certs as usual.
docker 1.12实现的swarm模式更简单,并且node之间使用TLS机制进行通信。
(2)
The self-awareness of the swarm is the biggest and most significant change. Every node in the swarm can reach every other node, and is able to route traffic where it needs to go. You no longer need to run your own load balancer and integrate it with a dynamic discovery agent, using tools like Nginx and Interlock.
Now if a node receives a request which it can’t fulfil, because it isn’t running an instance of the container that can process the request, it routes the request on to a node which can fulfil it. This is transparent to the consumer, all they see is the response to their request, they don’t know about any redirections that happened within the swarm.
docker 1.12的swarm模式自带“self-awareness”和“load-balance”机制,并且可以把请求路由到符合要求的node。
docker 1.12的swarm模式相关的文件默认存放在/var/lib/docker/swarm这个文件夹下面。
关于docker 1.12的swarm模式的demo,可参考这个video。
Update:docker 1.12其实是利用swarmkit这个project来实现docker swarm cluster功能(相关代码位于daemon/cluster这个目录)。
参考资料:
The relation between “docker/swarm” and “docker/swarmkit”;
Comparing Swarm, Swarmkit and Swarm Mode;
Docker 1.12 Swarm Mode – Under the hood。
GNU make的target默认都是文件名。而像all,clean等等操作并不产生同名的文件,则通常把它们归于phony target,即“假的”target:
.PHONY: all clean
具体可参考这篇帖子。
以下命令参考自这篇文章:
(1)清除已经终止的container:
docker rm -v $(docker ps --filter status=exited -q)
(2)清除已经没用的volume:
docker volume rm $(docker volume ls -q -f 'dangling=true')
(3)清除已经没用的image:
docker rmi $(docker images -f "dangling=true" -q) (4)清除所有的container(包括正在运行的和已经退出的):
docker rm -f $(docker ps -a | awk 'NR > 1 {print $1}')从这篇文章介绍了什么是CUDA:
CUDA® is a parallel computing platform and programming model invented by NVIDIA. It enables dramatic increases in computing performance by harnessing the power of the graphics processing unit (GPU).
CUDA是NVIDIA提供的一个并行计算平台和模型,可以让程序更好地利用GPU。下面这段话则很好地解释了什么是“GPU computing”:
Using high-level languages, GPU-accelerated applications run the sequential part of their workload on the CPU – which is optimized for single-threaded performance – while accelerating parallel processing on the GPU. This is called “GPU computing.”
FreeBSD中sysctl家族的函数定义:
#include <sys/types.h>
#include <sys/sysctl.h>
int
sysctl(const int *name, u_int namelen, void *oldp, size_t *oldlenp,
const void *newp, size_t newlen);
int
sysctlbyname(const char *name, void *oldp, size_t *oldlenp,
const void *newp, size_t newlen);
int
sysctlnametomib(const char *name, int *mibp, size_t *sizep);
在sysctl函数参数中,name和namelen用来表明内核参数ID;oldp和oldlenp用来存储当前内核参数的值;而newp和newlen则用来设置新的内核参数值。如果不需要的话,可以把相应的值置成NULL。
看一下sysctlbyname的实现:
int
sysctlbyname(const char *name, void *oldp, size_t *oldlenp,
const void *newp, size_t newlen)
{
int real_oid[CTL_MAXNAME+2];
size_t oidlen;
oidlen = sizeof(real_oid) / sizeof(int);
if (sysctlnametomib(name, real_oid, &oidlen) < 0)
return (-1);
return (sysctl(real_oid, oidlen, oldp, oldlenp, newp, newlen));
}
可以看到,sysctlbyname首先通过sysctlnametomib获得真正的ID,接着调用sysctl完成想要的工作。
参考资料:
SYSCTL(3);
Grokking SYSCTL and the Art of Smashing Kernel Variables。
Go语言的context package可以把一组用来处理同一请求的函数和goroutine通过context.Context这个类型的变量关联起来,并提供了取消(cancelation)和超时(timeout)机制。个人觉得Sameer Ajmani的这篇文档:Cancelation, Context, and Plumbing写得很清晰,更容易让人理解context package。
更新1:下列关于Context的定义选自Go Concurrency Patterns: Context:
// A Context carries a deadline, cancelation signal, and request-scoped values
// across API boundaries. Its methods are safe for simultaneous use by multiple
// goroutines.
type Context interface {
// Done returns a channel that is closed when this Context is canceled
// or times out.
Done() <-chan struct{}
// Err indicates why this context was canceled, after the Done channel
// is closed.
Err() error
// Deadline returns the time when this Context will be canceled, if any.
Deadline() (deadline time.Time, ok bool)
// Value returns the value associated with key or nil if none.
Value(key interface{}) interface{}
}
四个函数定义如下:
a)Done函数返回一个只读channel,因此对其操作只有close。而这个channel只在Context被cancel或timeout的情况下才会被close;
b)Err则是在Done channel被close后,用来获得close的原因,并返回一个non-nil的值:context canceled或context deadline exceeded;
c)Deadline返回Context被cancel的时间。如果ok为false,则表明没有设置deadline;
d)Value返回同key绑定的值,如果没有相应的值,则返回nil。
更新2:简单地分析一下源码:
// An emptyCtx is never canceled, has no values, and has no deadline. It is not
// struct{}, since vars of this type must have distinct addresses.
type emptyCtx int
func (*emptyCtx) Deadline() (deadline time.Time, ok bool) {
return
}
func (*emptyCtx) Done() <-chan struct{} {
return nil
}
func (*emptyCtx) Err() error {
return nil
}
func (*emptyCtx) Value(key interface{}) interface{} {
return nil
}
func (e *emptyCtx) String() string {
switch e {
case background:
return "context.Background"
case todo:
return "context.TODO"
}
return "unknown empty Context"
}
var (
background = new(emptyCtx)
todo = new(emptyCtx)
)
context.Background()和context.TODO()所返回的其实都是一个指向emptyCtx类型变量的指针。
再看一下WithCancel()函数实现:
// WithCancel returns a copy of parent with a new Done channel. The returned
// context's Done channel is closed when the returned cancel function is called
// or when the parent context's Done channel is closed, whichever happens first.
//
// Canceling this context releases resources associated with it, so code should
// call cancel as soon as the operations running in this Context complete.
func WithCancel(parent Context) (ctx Context, cancel CancelFunc) {
c := newCancelCtx(parent)
propagateCancel(parent, c)
return c, func() { c.cancel(true, Canceled) }
}
// newCancelCtx returns an initialized cancelCtx.
func newCancelCtx(parent Context) *cancelCtx {
return &cancelCtx{
Context: parent,
done: make(chan struct{}),
}
}
而cancelCtx定义如下:
// A cancelCtx can be canceled. When canceled, it also cancels any children
// that implement canceler.
type cancelCtx struct {
Context
done chan struct{} // closed by the first cancel call.
mu sync.Mutex
children map[canceler]bool // set to nil by the first cancel call
err error // set to non-nil by the first cancel call
}
每次调用WithCancel函数,新生成的Context会包含“父Context”以及一个新的done channel。
propagateCancel()函数实现如下:
// propagateCancel arranges for child to be canceled when parent is.
func propagateCancel(parent Context, child canceler) {
if parent.Done() == nil {
return // parent is never canceled
}
if p, ok := parentCancelCtx(parent); ok {
p.mu.Lock()
if p.err != nil {
// parent has already been canceled
child.cancel(false, p.err)
} else {
if p.children == nil {
p.children = make(map[canceler]bool)
}
p.children[child] = true
}
p.mu.Unlock()
} else {
go func() {
select {
case <-parent.Done():
child.cancel(false, parent.Err())
case <-child.Done():
}
}()
}
}
这个函数就是把新生成的Context加到父Context的children成员中,这样可以形成“级联”的cancel操作。
其它参考资料:
package context;
Concurrent patterns in Golang: Context;
Context and Cancellation of goroutines。
本文是Go Concurrency Patterns: Pipelines and cancellation的读书笔记:
(1)Pipeline定义:
What is a pipeline?
There’s no formal definition of a pipeline in Go; it’s just one of many kinds of concurrent programs. Informally, a pipeline is a series of stages connected by channels, where each stage is a group of goroutines running the same function. In each stage, the goroutines
receive values from upstream via inbound channels
perform some function on that data, usually producing new values
send values downstream via outbound channelsEach stage has any number of inbound and outbound channels, except the first and last stages, which have only outbound or inbound channels, respectively. The first stage is sometimes called the source or producer; the last stage, the sink or consumer.
在Go并发编程中,pipeline由一系列stage组成,而每个stage则由一组执行相同功能的goroutine组成,各个stage之间通过channel进行通信。goroutine从inbound channels从上游stage接收消息,经过一番处理后,利用outbound channels向下游stage发送消息。每个stage可以包含若干个inbound和outbound channels,但是第一个stage只能有一个outbound channel,最后一个stage只能有一个inbound channel。
(2)一个基本的pipeline例子:
package main
import "fmt"
func gen(nums ...int) <-chan int {
out := make(chan int)
go func() {
for _, n := range nums {
out <- n
}
close(out)
}()
return out
}
func sq(in <-chan int) <-chan int {
out := make(chan int)
go func() {
for n := range in {
out <- n * n
}
close(out)
}()
return out
}
func main() {
// Set up the pipeline.
c := gen(2, 3)
out := sq(c)
// Consume the output.
fmt.Println(<-out) // 4
fmt.Println(<-out) // 9
}
执行结果:
4
9
gen()是第一个stage并产生一个outbound channel。sq()是第二个stage,从gen()的outbound channel接受输入,并产生一个新的outbound channel,把每个数的平方发送到这个outbound channel中。main()是最后一个stage,接收sq()的outbound channel的输入,并把结果打印出来。
(3)fan-out和fan-inFan-out和fan-in的定义:
Multiple functions can read from the same channel until that channel is closed; this is called fan-out. This provides a way to distribute work amongst a group of workers to parallelize CPU use and I/O.
A function can read from multiple inputs and proceed until all are closed by multiplexing the input channels onto a single channel that’s closed when all the inputs are closed. This is called fan-in.
多个函数从同一个channel读取叫fan-out;一个函数从多个channel读取并把处理结果发送到一个channel中,称之为fan-in。举例如下:
package main
import (
"fmt"
"sync"
)
func gen(nums ...int) <-chan int {
out := make(chan int)
go func() {
for _, n := range nums {
out <- n
}
close(out)
}()
return out
}
func sq(in <-chan int) <-chan int {
out := make(chan int)
go func() {
for n := range in {
out <- n * n
}
close(out)
}()
return out
}
func merge(cs ...<-chan int) <-chan int {
var wg sync.WaitGroup
out := make(chan int)
// Start an output goroutine for each input channel in cs. output
// copies values from c to out until c is closed, then calls wg.Done.
output := func(c <-chan int) {
for n := range c {
out <- n
}
wg.Done()
}
wg.Add(len(cs))
for _, c := range cs {
go output(c)
}
// Start a goroutine to close out once all the output goroutines are
// done. This must start after the wg.Add call.
go func() {
wg.Wait()
close(out)
}()
return out
}
func main() {
in := gen(2, 3)
// Distribute the sq work across two goroutines that both read from in.
c1 := sq(in)
c2 := sq(in)
// Consume the merged output from c1 and c2.
for n := range merge(c1, c2) {
fmt.Println(n) // 4 then 9, or 9 then 4
}
}
以下代码称之为fan-out:
// Distribute the sq work across two goroutines that both read from in.
c1 := sq(in)
c2 := sq(in)
而merge函数的工作即为fan-in。
(3)通知上游stage取消发送操作。例子如下:
package main
import (
"fmt"
"sync"
)
func gen(done <-chan struct{}, nums ...int) <-chan int {
out := make(chan int)
go func() {
defer close(out)
for _, n := range nums {
select {
case out <- n:
case <- done:
return
}
}
}()
return out
}
func sq(done <-chan struct{}, in <-chan int) <-chan int {
out := make(chan int)
go func() {
defer close(out)
for n := range in {
select {
case out <- n * n:
case <-done:
return
}
}
}()
return out
}
func merge(done <-chan struct{}, cs ...<-chan int) <-chan int {
var wg sync.WaitGroup
out := make(chan int)
// Start an output goroutine for each input channel in cs. output
// copies values from c to out until c or done is closed, then calls
// wg.Done.
output := func(c <-chan int) {
defer wg.Done()
for n := range c {
select {
case out <- n:
case <-done:
return
}
}
}
wg.Add(len(cs))
for _, c := range cs {
go output(c)
}
// Start a goroutine to close out once all the output goroutines are
// done. This must start after the wg.Add call.
go func() {
wg.Wait()
close(out)
}()
return out
}
func main() {
// Set up a done channel that's shared by the whole pipeline,
// and close that channel when this pipeline exits, as a signal
// for all the goroutines we started to exit.
done := make(chan struct{})
defer close(done)
in := gen(done, 2, 3)
// Distribute the sq work across two goroutines that both read from in.
c1 := sq(done, in)
c2 := sq(done, in)
// Consume the first value from output.
out := merge(done, c1, c2)
fmt.Println(<-out) // 4 or 9
}
构建一个done channel,调用close函数关闭done channel,用来通知上游stage停止发送。
(4)Pipeline构建的原则:
Here are the guidelines for pipeline construction:
stages close their outbound channels when all the send operations are done.
stages keep receiving values from inbound channels until those channels are closed or the senders are unblocked.Pipelines unblock senders either by ensuring there’s enough buffer for all the values that are sent or by explicitly signalling senders when the receiver may abandon the channel.
本文是Go Concurrency Patterns: Pipelines and cancellation的读书笔记:
(1)Pipeline定义:
What is a pipeline?
There’s no formal definition of a pipeline in Go; it’s just one of many kinds of concurrent programs. Informally, a pipeline is a series of stages connected by channels, where each stage is a group of goroutines running the same function. In each stage, the goroutines
receive values from upstream via inbound channels
perform some function on that data, usually producing new values
send values downstream via outbound channelsEach stage has any number of inbound and outbound channels, except the first and last stages, which have only outbound or inbound channels, respectively. The first stage is sometimes called the source or producer; the last stage, the sink or consumer.
在Go并发编程中,pipeline由一系列stage组成,而每个stage则由一组执行相同功能的goroutine组成,各个stage之间通过channel进行通信。goroutine从inbound channels从上游stage接收消息,经过一番处理后,利用outbound channels向下游stage发送消息。每个stage可以包含若干个inbound和outbound channels,但是第一个stage只能有一个outbound channel,最后一个stage只能有一个inbound channel。
(2)一个基本的pipeline例子:
package main
import "fmt"
func gen(nums ...int) <-chan int {
out := make(chan int)
go func() {
for _, n := range nums {
out <- n
}
close(out)
}()
return out
}
func sq(in <-chan int) <-chan int {
out := make(chan int)
go func() {
for n := range in {
out <- n * n
}
close(out)
}()
return out
}
func main() {
// Set up the pipeline.
c := gen(2, 3)
out := sq(c)
// Consume the output.
fmt.Println(<-out) // 4
fmt.Println(<-out) // 9
}
执行结果:
4
9
gen()是第一个stage并产生一个outbound channel。sq()是第二个stage,从gen()的outbound channel接受输入,并产生一个新的outbound channel,把每个数的平方发送到这个outbound channel中。main()是最后一个stage,接收sq()的outbound channel的输入,并把结果打印出来。
(3)fan-out和fan-inFan-out和fan-in的定义:
Multiple functions can read from the same channel until that channel is closed; this is called fan-out. This provides a way to distribute work amongst a group of workers to parallelize CPU use and I/O.
A function can read from multiple inputs and proceed until all are closed by multiplexing the input channels onto a single channel that’s closed when all the inputs are closed. This is called fan-in.
多个函数从同一个channel读取叫fan-out;一个函数从多个channel读取并把处理结果发送到一个channel中,称之为fan-in。举例如下:
package main
import (
"fmt"
"sync"
)
func gen(nums ...int) <-chan int {
out := make(chan int)
go func() {
for _, n := range nums {
out <- n
}
close(out)
}()
return out
}
func sq(in <-chan int) <-chan int {
out := make(chan int)
go func() {
for n := range in {
out <- n * n
}
close(out)
}()
return out
}
func merge(cs ...<-chan int) <-chan int {
var wg sync.WaitGroup
out := make(chan int)
// Start an output goroutine for each input channel in cs. output
// copies values from c to out until c is closed, then calls wg.Done.
output := func(c <-chan int) {
for n := range c {
out <- n
}
wg.Done()
}
wg.Add(len(cs))
for _, c := range cs {
go output(c)
}
// Start a goroutine to close out once all the output goroutines are
// done. This must start after the wg.Add call.
go func() {
wg.Wait()
close(out)
}()
return out
}
func main() {
in := gen(2, 3)
// Distribute the sq work across two goroutines that both read from in.
c1 := sq(in)
c2 := sq(in)
// Consume the merged output from c1 and c2.
for n := range merge(c1, c2) {
fmt.Println(n) // 4 then 9, or 9 then 4
}
}
以下代码称之为fan-out:
// Distribute the sq work across two goroutines that both read from in.
c1 := sq(in)
c2 := sq(in)
而merge函数的工作即为fan-in。
(3)通知上游stage取消发送操作。例子如下:
package main
import (
"fmt"
"sync"
)
func gen(done <-chan struct{}, nums ...int) <-chan int {
out := make(chan int)
go func() {
defer close(out)
for _, n := range nums {
select {
case out <- n:
case <- done:
return
}
}
}()
return out
}
func sq(done <-chan struct{}, in <-chan int) <-chan int {
out := make(chan int)
go func() {
defer close(out)
for n := range in {
select {
case out <- n * n:
case <-done:
return
}
}
}()
return out
}
func merge(done <-chan struct{}, cs ...<-chan int) <-chan int {
var wg sync.WaitGroup
out := make(chan int)
// Start an output goroutine for each input channel in cs. output
// copies values from c to out until c or done is closed, then calls
// wg.Done.
output := func(c <-chan int) {
defer wg.Done()
for n := range c {
select {
case out <- n:
case <-done:
return
}
}
}
wg.Add(len(cs))
for _, c := range cs {
go output(c)
}
// Start a goroutine to close out once all the output goroutines are
// done. This must start after the wg.Add call.
go func() {
wg.Wait()
close(out)
}()
return out
}
func main() {
// Set up a done channel that's shared by the whole pipeline,
// and close that channel when this pipeline exits, as a signal
// for all the goroutines we started to exit.
done := make(chan struct{})
defer close(done)
in := gen(done, 2, 3)
// Distribute the sq work across two goroutines that both read from in.
c1 := sq(done, in)
c2 := sq(done, in)
// Consume the first value from output.
out := merge(done, c1, c2)
fmt.Println(<-out) // 4 or 9
}
构建一个done channel,调用close函数关闭done channel,用来通知上游stage停止发送。
(4)Pipeline构建的原则:
Here are the guidelines for pipeline construction:
stages close their outbound channels when all the send operations are done.
stages keep receiving values from inbound channels until those channels are closed or the senders are unblocked.Pipelines unblock senders either by ensuring there’s enough buffer for all the values that are sent or by explicitly signalling senders when the receiver may abandon the channel.