Kubernetes is an open source project that brings ‘Google style’ cluster management capabilities to the world of virtual machines, or ‘on the metal’ scenarios. It works very well with modern operating system environments (like CoreOS or Red Hat Atomic) that offer up lightweight computing ‘nodes’ that are managed for you. It is written in Golang and is lightweight, modular, portable and extensible. We (the Kubernetes team) are working with a number of different technology companies (including Mesosphere who curate the Mesos open source project) to establish Kubernetes as the standard way to interact with computing clusters. The idea is to reproduce the patterns that we see people needing to build cluster applications based on our experience at Google. Some of these concepts include:
pods — a way to group containers together
replication controllers — a way to handle the lifecycle of containers
labels — a way to find and query containers, and
services — a set of containers performing a common function.
So with Kubernetes alone you will have something that is simple, easy to get up-and-running, portable and extensible that adds ‘cluster’ as a noun to the things that you manage in the lightest weight manner possible. Run an application on a cluster, and stop worrying about an individual machine. In this case, cluster is a flexible resource just like a VM. It is a logical computing unit. Turn it up, use it, resize it, turn it down quickly and easily.
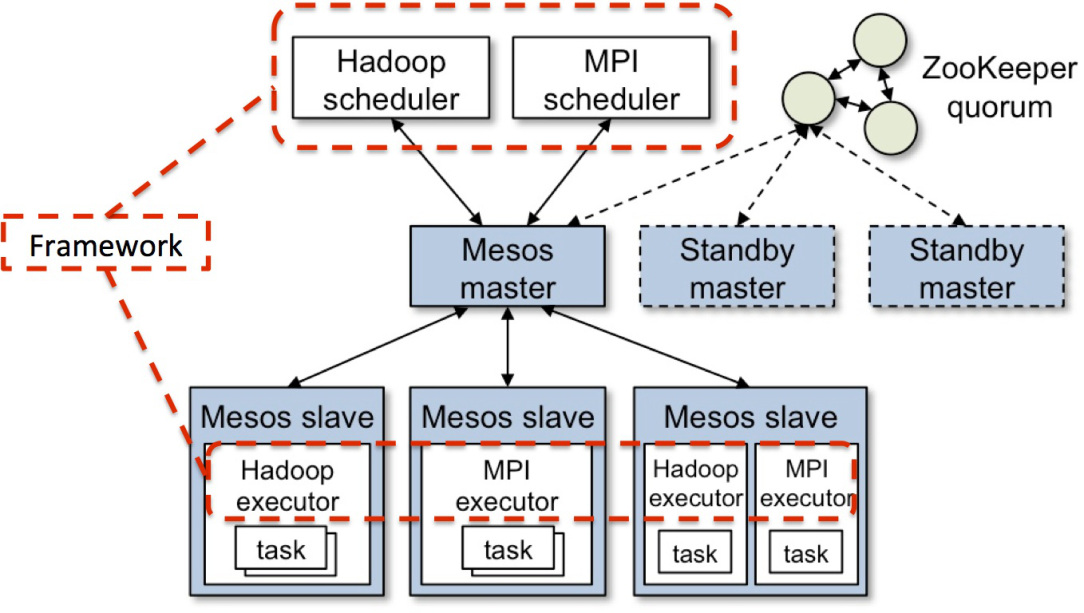
With Mesos, there is a fair amount of overlap in terms of the basic vision, but the products are at quite different points in their lifecycle and have different sweet spots. Mesos is a distributed systems kernel that stitches together a lot of different machines into a logical computer. It was born for a world where you own a lot of physical resources to create a big static computing cluster. The great thing about it is that lots of modern scalable data processing application run well on Mesos (Hadoop, Kafka, Spark) and it is nice because you can run them all on the same basic resource pool, along with your new age container packaged apps. It is somewhat more heavy weight than the Kubernetes project, but is getting easier and easier to manage thanks to the work of folks like Mesosphere.
Now what gets really interesting is that Mesos is currently being adapted to add a lot of the Kubernetes concepts and to support the Kubernetes API. So it will be a gateway to getting more capabilities for your Kubernetes app (high availability master, more advanced scheduling semantics, ability to scale to a very large number of nodes) if you need them, and is well suited to run production workloads (Kubernetes is still in an alpha state).
When asked, I tend to say:
Kubernetes is a great place to start if you are new to the clustering world; it is the quickest, easiest and lightest way to kick the tires and start experimenting with cluster oriented development. It offers a very high level of portability since it is being supported by a lot of different providers (Microsoft, IBM, Red Hat, CoreOs, MesoSphere, VMWare, etc).
If you have existing workloads (Hadoop, Spark, Kafka, etc), Mesos gives you a framework that let’s you interleave those workloads with each other, and mix in a some of the new stuff including Kubernetes apps.
Mesos gives you an escape valve if you need capabilities that are not yet implemented by the community in the Kubernetes framework.