这篇笔记摘自Professional CUDA C Programming:
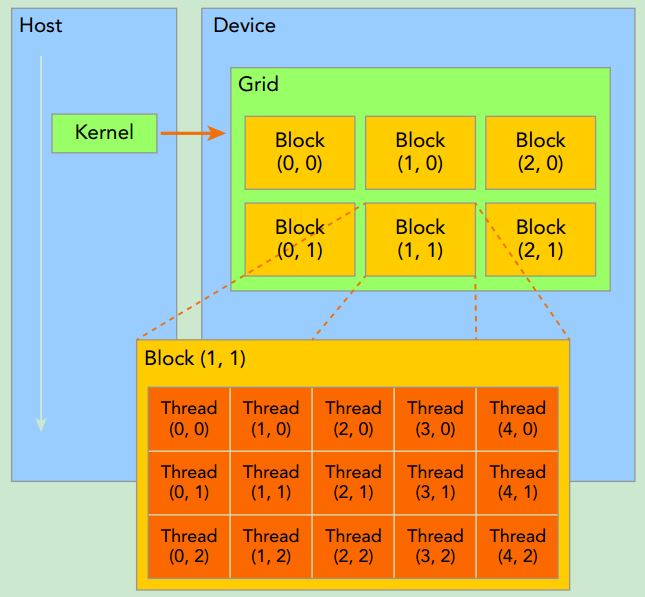
Warps are the basic unit of execution in an SM. When you launch a grid of thread blocks, the thread blocks in the grid are distributed among SMs. Once a thread block is scheduled to an SM, threads in the thread block are further partitioned into warps. A warp consists of 32 consecutive threads and all threads in a warp are executed in Single Instruction Multiple Thread (SIMT) fashion; that is, all threads execute the same instruction, and each thread carries out that operation on its own private data. The following figure illustrates the relationship between the logical view and hardware view of a thread block.
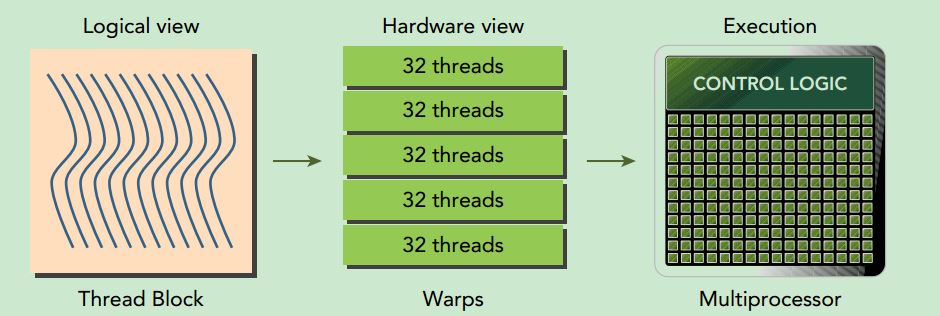
From the logical perspective, a thread block is a collection of threads organized in a 1D, 2D, or 3D layout.
From the hardware perspective, a thread block is a 1D collection of warps. Threads in a thread block are organized in a 1D layout, and each set of 32 consecutive threads forms a warp.
在实际的执行中,每个block会被切割成一个一个的warp,而warp中的thread会同步运行。
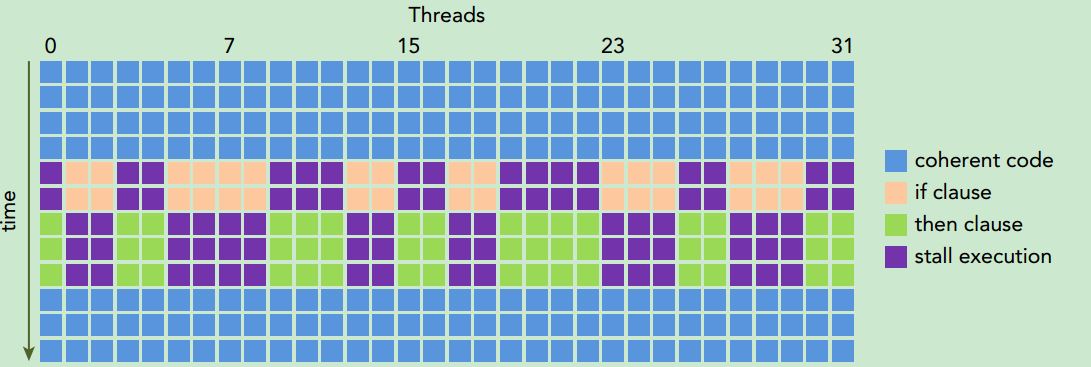
Threads in the same warp executing different instructions is referred to as warp divergence.
If threads of a warp diverge, the warp serially executes each branch path, disabling threads that do not take that path. Warp divergence can cause signifcantly degraded performance.
Take note that branch divergence occurs only within a warp. Different conditional values in different warps do not cause warp divergence.
warp divergence只会发生在同一个warp中,参考下图:
The local execution context of a warp mainly consists of the following resources:
➤ Program counters
➤ Registers
➤ Shared memory
The execution context of each warp processed by an SM is maintained on-chip during the entire lifetime of the warp. Therefore, switching from one execution context to another has no cost.Each SM has a set of 32-bit registers stored in a register file that are partitioned among threads, and a fixed amount of shared memory that is partitioned among thread blocks. The number of thread blocks and warps that can simultaneously reside on an SM for a given kernel depends on the number of registers and amount of shared memory available on the SM and required by the kernel.
thread共享register,block共享shared memory。
A thread block is called an active block when compute resources, such as registers and shared memory, have been allocated to it. The warps it contains are called active warps. Active warps can be further classifed into the following three types:
➤ Selected warp
➤ Stalled warp
➤ Eligible warp
The warp schedulers on an SM select active warps on every cycle and dispatch them to execution units. A warp that is actively executing is called a selected warp. If an active warp is ready for execution but not currently executing, it is an eligible warp. If a warp is not ready for execution, it is a stalled warp. A warp is eligible for execution if both of the following two conditions is met:
➤ Thirty-two CUDA cores are available for execution.
➤ All arguments to the current instruction are ready.
GUIDELINES FOR GRID AND BLOCK SIZE
Using these guidelines will help your application scale on current and future devices:
➤ Keep the number of threads per block a multiple of warp size (32).
➤ Avoid small block sizes: Start with at least 128 or 256 threads per block.
➤ Adjust block size up or down according to kernel resource requirements.
➤ Keep the number of blocks much greater than the number of SMs to expose sufficient parallelism to your device.
➤ Conduct experiments to discover the best execution configuration and resource usage.