本文摘自Introduction To SAP HANA Database- For Beginners。
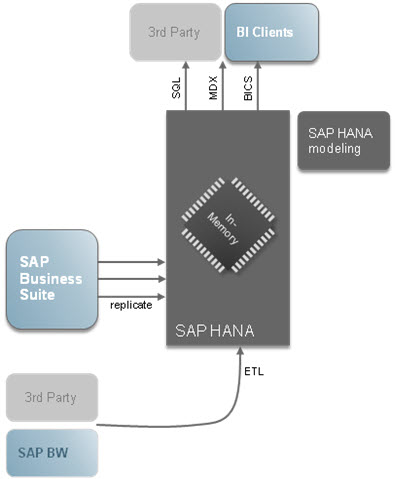
SAP HANA是一个in-memory database,它包含下列特性:
It is a combination of hardware and software made to process massive real time data using In-Memory computing.
It combines row-based, column-based database technology.
Data now resides in main-memory (RAM) and no longer on a hard disk.
It’s best suited for performing real-time analytics, and developing and deploying real-time applications.
SAP HANA体系结构如下图所示: