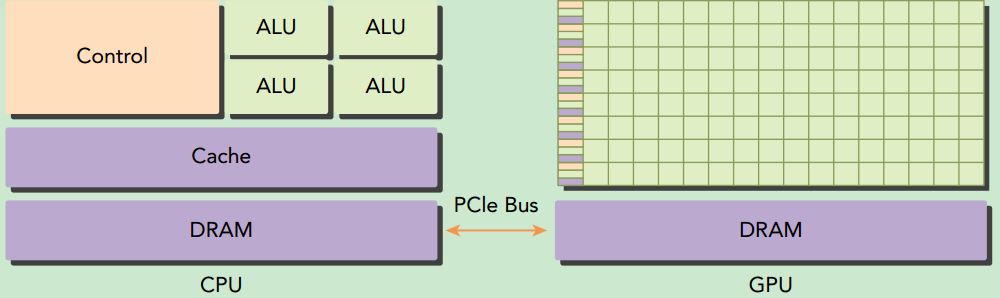
这篇笔记摘自Professional CUDA C Programming:
A typical CUDA program structure consists of five main steps:
1. Allocate GPU memories.
2. Copy data from CPU memory to GPU memory.
3. Invoke the CUDA kernel to perform program-specific computation.
4. Copy data back from GPU memory to CPU memory.
5. Destroy GPU memories.CUDA exposes you to the concepts of both memory hierarchy and thread hierarchy, extending your ability to control thread execution and scheduling to a greater degree, using:
➤ Memory hierarchy structure
➤ Thread hierarchy structure
For example, a special memory, called shared memory, is exposed by the CUDA programming model. Shared memory can be thought of as a software-managed cache, which provides great speedup by conserving bandwidth to main memory. With shared memory, you can control the locality of your code directly.When writing a parallel program in ANSI C, you need to explicitly organize your threads with either pthreads or OpenMP, two well-known techniques to support parallel programming on most processor architectures and operating systems. When writing a program in CUDA C, you actually just write a piece of serial code to be called by only one thread. The GPU takes this kernel and makes it parallel by launching thousands of threads, all performing that same computation. The CUDA programming model provides you with a way to organize your threads hierarchically. Manipulating this organization directly affects the order in which threads are executed on the GPU. Because CUDA C is an extension of C, it is often straightforward to port C programs to CUDA C. Conceptually, peeling off the loops of your code yields the kernel code for a CUDA C implementation.
CUDA abstracts away the hardware details and does not require applications to be mapped to traditional graphics APIs. At its core are three key abstractions: a hierarchy of thread groups, a hierarchy of memory groups, and barrier synchronization, which are exposed to you as a minimal set of language extensions.