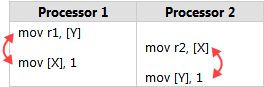
SystemTap也提供associate array,并且必须是global变量:
global array_name[index_expression]
最多可以有9个index_expression,它们之间用,分割:
device[pid(),execname(),uid(),ppid(),"W"] = devname
可以用if语句来检查某个key是否存在:
if([index_expression] in array_name) statement
以下面程序为例:
# cat test.stp
#!/usr/bin/stap
global reads
probe vfs.read
{
reads[execname()] ++
}
probe timer.s(3)
{
printf("=======\n")
foreach (count in reads+)
printf("%s : %d \n", count, reads[count])
if(["stapio"] in reads) {
printf("stapio read detected, exiting\n")
exit()
}
}
# ./test.stp
=======
systemd-udevd : 4
gmain : 5
avahi-daemon : 11
stapio : 17
stapio read detected, exiting
可以用delete操作来删除一个元素或是整个数组:
delete removes an element.
The following statement removes from ARRAY the element specified by the index tuple. The value will no longer be available, and subsequent iterations will not report the element. It is not an error to delete an element that does not exist.
delete ARRAY[INDEX1, INDEX2, …]
The following syntax removes all elements from ARRAY:
delete ARRAY
foreach是输出associate array的一个重要方法:
General syntax:
foreach (VAR in ARRAY) STMT
The foreach statement loops over each element of a named global array, assigning the current key to VAR. The array must not be modified within the statement. If you add a single plus (+) or minus (-) operator after the VAR or the ARRAY identifier, the iteration order will be sorted by the ascending or descending index or value.
The following statement behaves the same as the first example, except it is used when an array is indexed with a tuple of keys. Use a sorting suffix on at most one VAR or ARRAY identifier.
foreach ([VAR1, VAR2, …] in ARRAY) STMT
You can combine the first and second syntax to capture both the full tuple and the keys at the same time as follows.
foreach (VALUE = [VAR1, VAR2, …] in ARRAY) STMT
The following statement is the same as the first example, except that the limit keyword limits the number of loop iterations to EXP times. EXP is evaluated once at the beginning of the loop.
foreach (VAR in ARRAY limit EXP) STMT
下面这个例子很好地解释了如何用foreach操作associate array:
# cat test.stp
#!/usr/bin/stap
global reads
probe vfs.read
{
reads[pid(), execname()]++
}
probe timer.s(3)
{
printf("======Total=====\n")
foreach ([pid, name] in reads)
printf("%d %s: %d\n", pid, name, reads[pid, name])
printf("======Another Total=====\n")
foreach (val = [pid, name] in reads)
printf("%d %s: %d\n", pid, name, val)
printf("======PID Ascending=====\n")
foreach ([pid+, name] in reads limit 3)
printf("%d %s: %d\n", pid, name, reads[pid, name])
printf("======Count Descending=====\n")
foreach ([pid, name] in reads- limit 3)
printf("%d %s: %d\n", pid, name, reads[pid, name])
exit()
}
执行如下:
# ./test.stp
======Total=====
14367 stapio: 17
976 gmain: 5
791 avahi-daemon: 11
806 irqbalance: 16
14368 systemd-udevd: 1
432 systemd-udevd: 3
======Another Total=====
14367 stapio: 17
976 gmain: 5
791 avahi-daemon: 11
806 irqbalance: 16
14368 systemd-udevd: 1
432 systemd-udevd: 3
======PID Ascending=====
432 systemd-udevd: 3
791 avahi-daemon: 11
806 irqbalance: 16
======Count Descending=====
14367 stapio: 17
806 irqbalance: 16
791 avahi-daemon: 11
首先输出associate array中的所有内容(使用两种不同方式),接着分别按PID升序和associate array中的value降序输出前三个。