An Efficient Matrix Transpose in CUDA C/C++中Coalesced Transpose Via Shared Memory一节讲述如何使用shared memory高效地实现matrix transpose:
__global__ void transposeCoalesced(float *odata, const float *idata)
{
__shared__ float tile[TILE_DIM][TILE_DIM];
int x = blockIdx.x * TILE_DIM + threadIdx.x;
int y = blockIdx.y * TILE_DIM + threadIdx.y;
int width = gridDim.x * TILE_DIM;
for (int j = 0; j < TILE_DIM; j += BLOCK_ROWS)
tile[threadIdx.y+j][threadIdx.x] = idata[(y+j)*width + x];
__syncthreads();
x = blockIdx.y * TILE_DIM + threadIdx.x; // transpose block offset
y = blockIdx.x * TILE_DIM + threadIdx.y;
for (int j = 0; j < TILE_DIM; j += BLOCK_ROWS)
odata[(y+j)*width + x] = tile[threadIdx.x][threadIdx.y + j];
}
(1)idata和odata分别是表示1024X1024个float元素的matrix的连续内存:
![IMG_20170216_145959[1]](https://nanxiao.me/wp-content/uploads/2017/02/IMG_20170216_1459591.jpg)
(2)关于blockIdx和threadIdx的取值,参考下面的图:
![IMG_20170216_151045[1]](https://nanxiao.me/wp-content/uploads/2017/02/IMG_20170216_1510451.jpg)
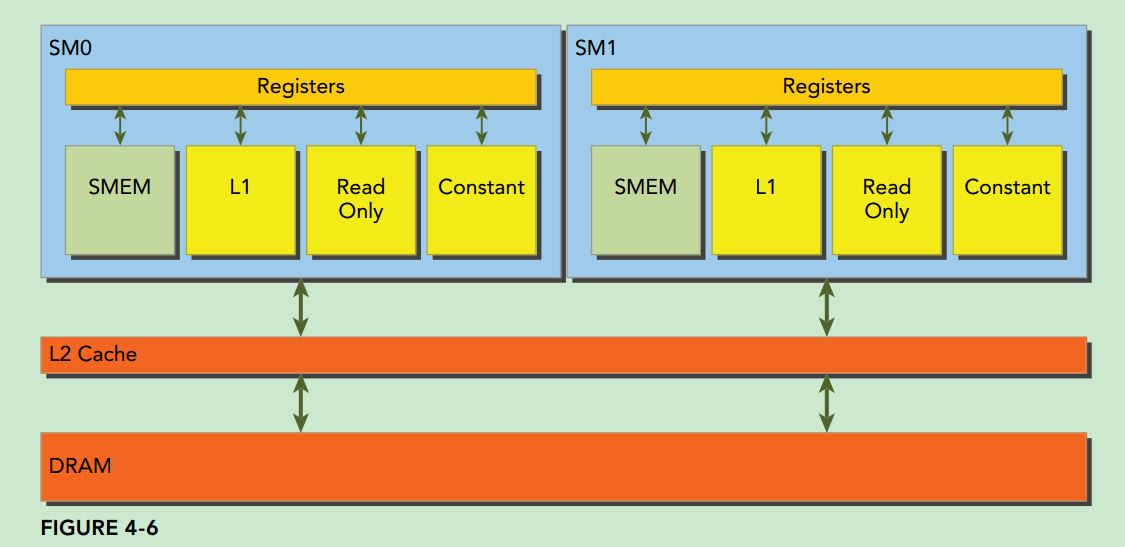
shared memory请参考下面的图:
![IMG_20170216_151058[1]](https://nanxiao.me/wp-content/uploads/2017/02/IMG_20170216_1510581.jpg)
(3)在下列代码中:
for (int j = 0; j < TILE_DIM; j += BLOCK_ROWS)
tile[threadIdx.y+j][threadIdx.x] = idata[(y+j)*width + x];
每一个block是32X8大小,需要循环4次,把一个block内容copy到tile这个shared memory中。idata是按行读取的,因此是coalesced。
![IMG_20170216_152636[1]](https://nanxiao.me/wp-content/uploads/2017/02/IMG_20170216_1526361.jpg)
(4)最难理解的在最后一部分:
x = blockIdx.y * TILE_DIM + threadIdx.x; // transpose block offset
y = blockIdx.x * TILE_DIM + threadIdx.y;
for (int j = 0; j < TILE_DIM; j += BLOCK_ROWS)
odata[(y+j)*width + x] = tile[threadIdx.x][threadIdx.y + j];
对比从idata读取数据和写数据到odata:
......
tile[threadIdx.y+j][threadIdx.x] = idata[(y+j)*width + x];
......
odata[(y+j)*width + x] = tile[threadIdx.x][threadIdx.y + j];
......
可以看到是把tile做了transpose的数据(行变列,列变行)传给odata。而确定需要把tile放到哪里位置的代码:
x = blockIdx.y * TILE_DIM + threadIdx.x; // transpose block offset
y = blockIdx.x * TILE_DIM + threadIdx.y;
假设blockIdx.x为31,blockIdx.y为0,threadIdx.x为1,threadIdx.y为2。根据上述代码,计算x和y:
x = 0 * 32 + 1;
y = 31 * 32 + 2;
根据下面的图,可以看到是把东北角的内容copy的西南角:
![IMG_20170216_155616[1]](https://nanxiao.me/wp-content/uploads/2017/02/IMG_20170216_1556161.jpg)