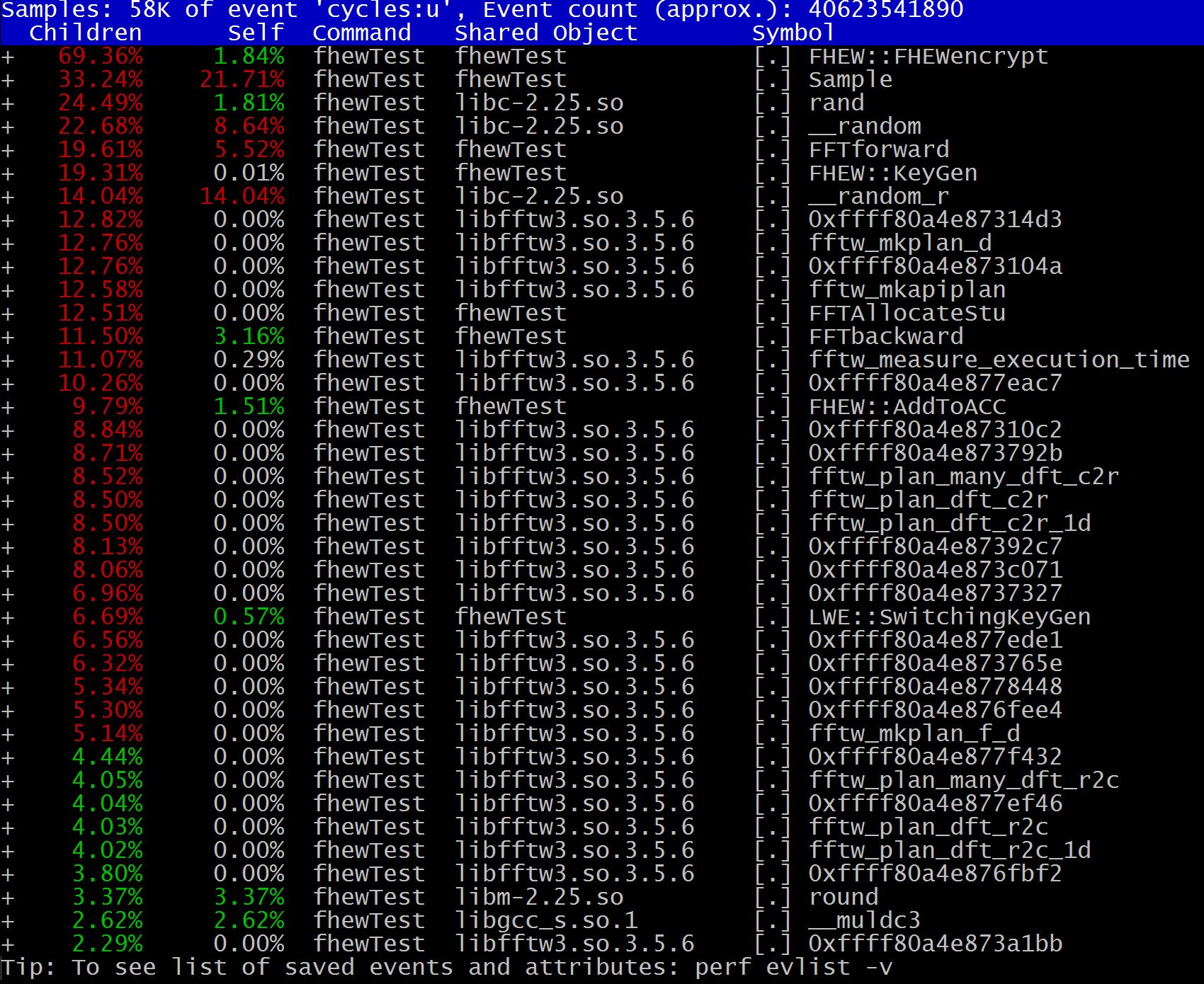
hotspot是KDAB发布的一个新的分析perf.data的工具。除了比perf report更直观外,其最大看点就是集成了火焰图,也就是FlameGraph。相信hotspot会对分析性能提供更大的帮助。
P.S.对比一下perf report:
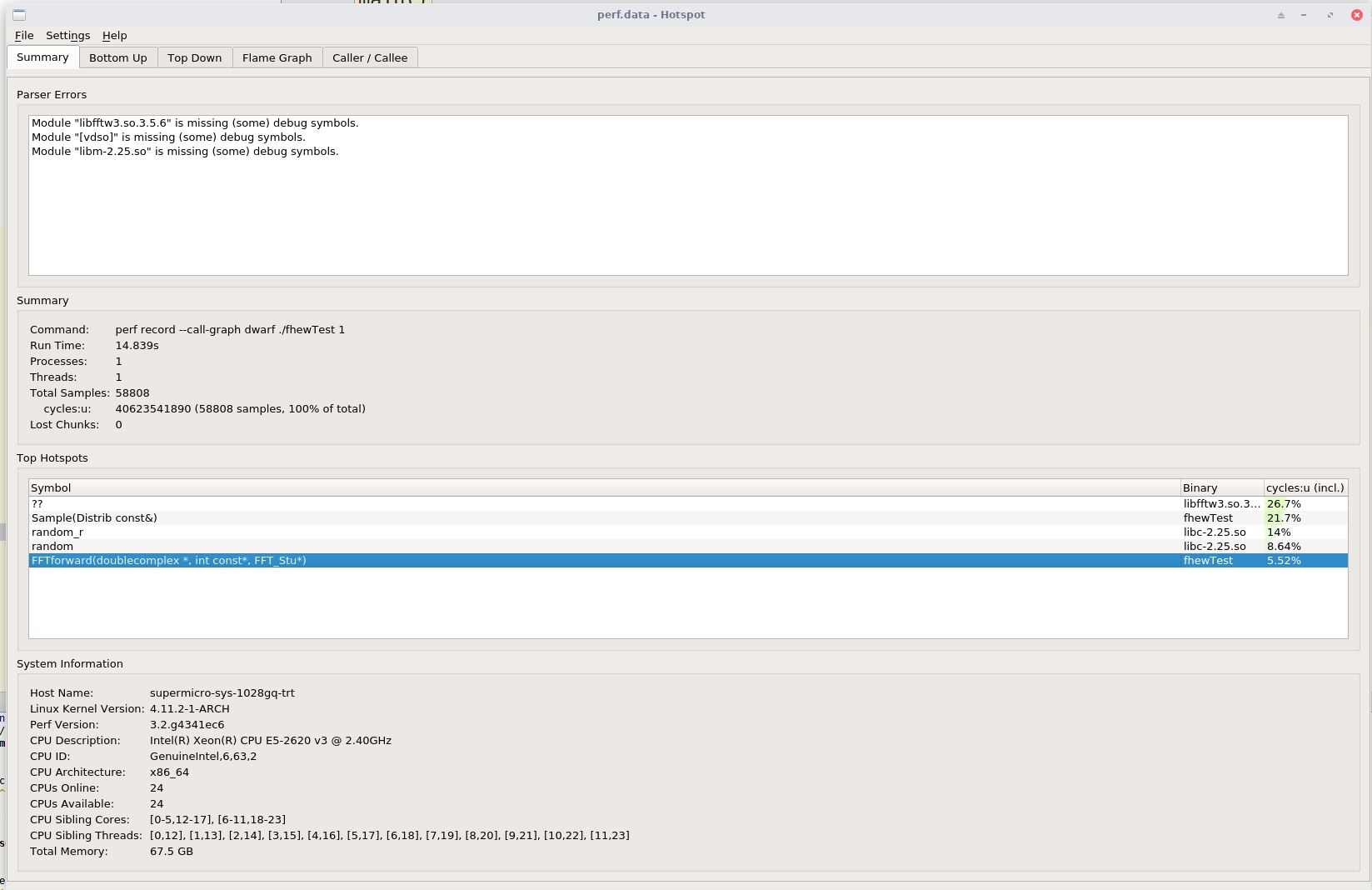
和hotspot:
hotspot是KDAB发布的一个新的分析perf.data的工具。除了比perf report更直观外,其最大看点就是集成了火焰图,也就是FlameGraph。相信hotspot会对分析性能提供更大的帮助。
P.S.对比一下perf report:
和hotspot:
perf trace有类似于strace功能,可以实时监控程序的系统调用:
# perf trace ./a.out
0.032 ( 0.002 ms): a.out/7673 brk( ) = 0x1e6b000
0.051 ( 0.005 ms): a.out/7673 access(filename: 0xb7c1cb00, mode: R ) = -1 ENOENT No such file or directory
0.063 ( 0.005 ms): a.out/7673 open(filename: 0xb7c1a7b7, flags: CLOEXEC ) = 3
0.070 ( 0.002 ms): a.out/7673 fstat(fd: 3, statbuf: 0x7ffffb72bc80 ) = 0
0.073 ( 0.004 ms): a.out/7673 mmap(len: 38436, prot: READ, flags: PRIVATE, fd: 3 ) = 0x7f18b7e15000
0.079 ( 0.001 ms): a.out/7673 close(fd: 3 ) = 0
0.087 ( 0.005 ms): a.out/7673 open(filename: 0xb7e21ec0, flags: CLOEXEC ) = 3
0.093 ( 0.003 ms): a.out/7673 read(fd: 3, buf: 0x7ffffb72be28, count: 832 ) = 832
0.099 ( 0.002 ms): a.out/7673 fstat(fd: 3, statbuf: 0x7ffffb72bcc0 ) = 0
0.102 ( 0.003 ms): a.out/7673 mmap(len: 8192, prot: READ|WRITE, flags: PRIVATE|ANONYMOUS, fd: -1 ) = 0x7f18b7e13000
0.110 ( 0.004 ms): a.out/7673 mmap(len: 2283024, prot: EXEC|READ, flags: PRIVATE|DENYWRITE, fd: 3 ) = 0x7f18b79cf000
0.116 ( 0.007 ms): a.out/7673 mprotect(start: 0x7f18b79fc000, len: 2093056 ) = 0
0.125 ( 0.005 ms): a.out/7673 mmap(addr: 0x7f18b7bfb000, len: 8192, prot: READ|WRITE, flags: PRIVATE|DENYWRITE|FIXED, fd: 3, off: 180224) = 0x7f18b7bfb000
0.142 ( 0.002 ms): a.out/7673 close(fd: 3 ) = 0
0.153 ( 0.006 ms): a.out/7673 open(filename: 0xb7e134c0, flags: CLOEXEC ) = 3
0.161 ( 0.003 ms): a.out/7673 read(fd: 3, buf: 0x7ffffb72bdf8, count: 832 ) = 832
0.165 ( 0.002 ms): a.out/7673 fstat(fd: 3, statbuf: 0x7ffffb72bc90 ) = 0
0.169 ( 0.005 ms): a.out/7673 mmap(len: 2216432, prot: EXEC|READ, flags: PRIVATE|DENYWRITE, fd: 3 ) = 0x7f18b77b1000
......Acme是Linux perf的maintainer,他的perf/core分支包含了perf工具的最新功能。所以如果想体验最新版本的perf,可以下载和编译Acme的perf:
git clone git://git.kernel.org/pub/scm/linux/kernel/git/acme/linux -b perf/core
cd linux/tools/perf
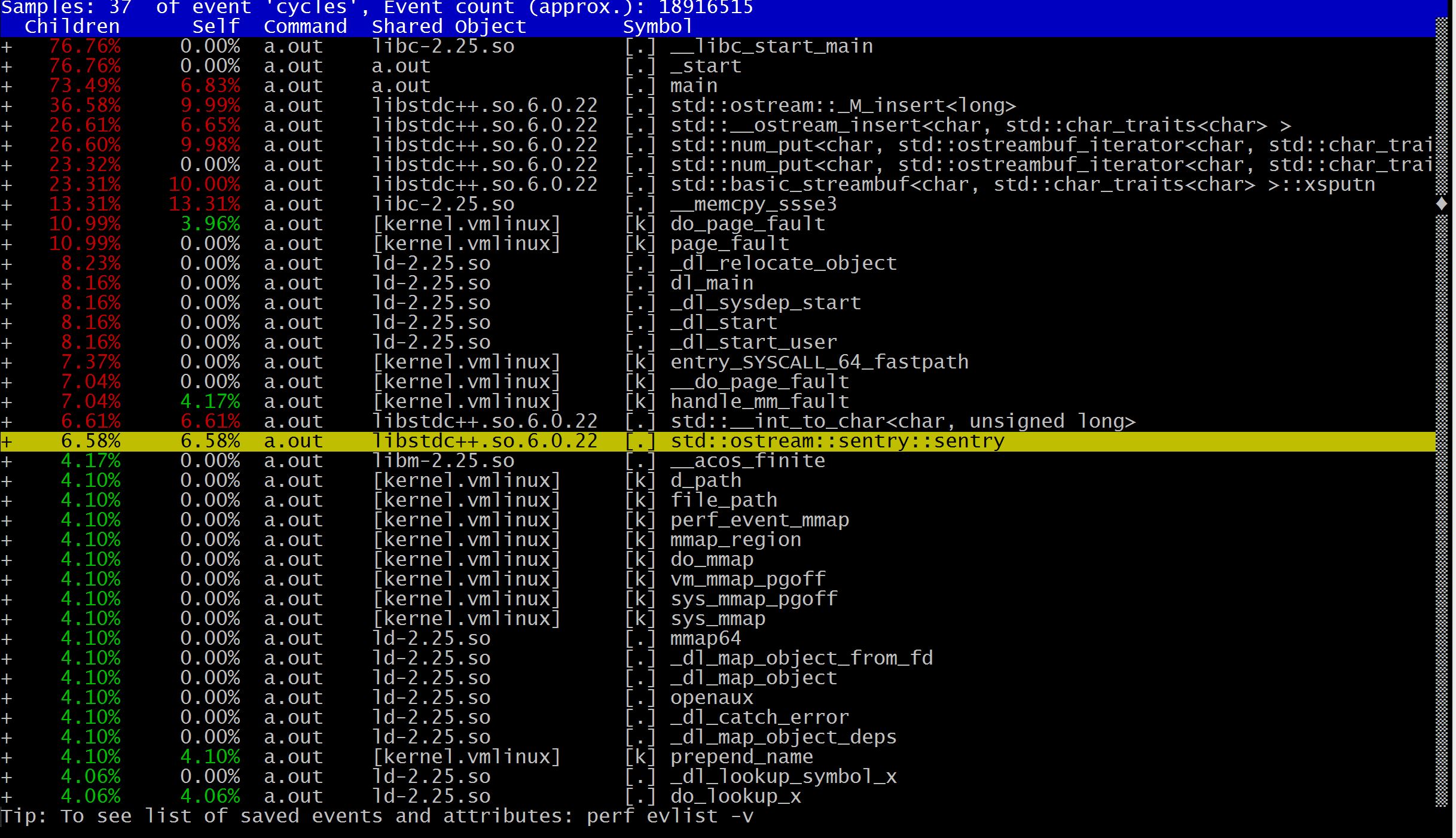
make在使用perf report命令显示profiling的结果时:
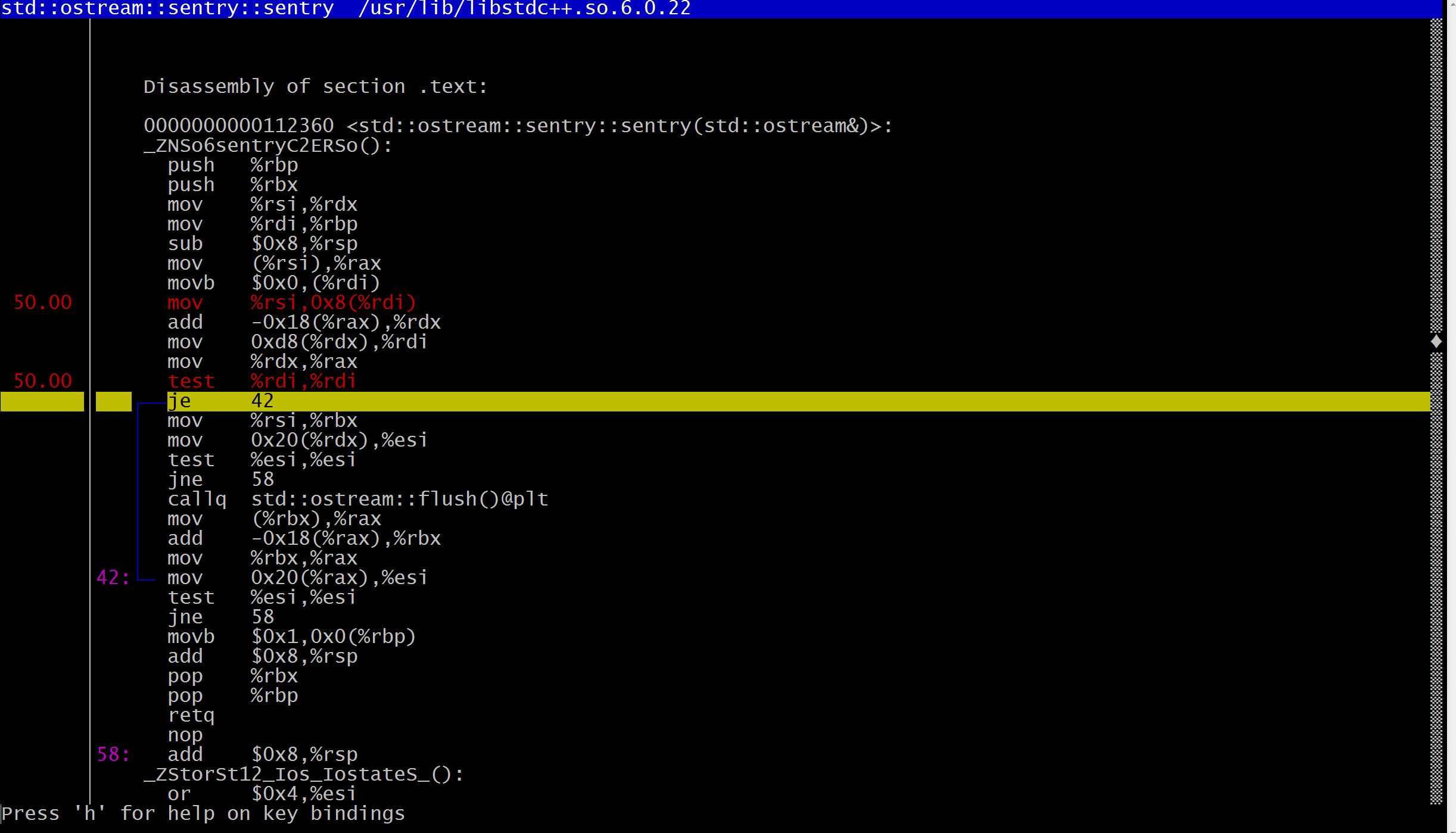
按a可以显示当前函数的profiling信息以及汇编指令:
使用perf record命令可以profile应用程序 (编译程序要使用-g,推荐使用-g -O2) :
perf record program [args]
或者在程序启动以后,使用-p pid选项:
perf record -p pid
默认情况下,信息会存在perf.data文件里,使用perf report命令可以解析这个文件:

哪些函数占用CPU比较多,一目了然。
另外,在使用perf record时可以加--call-graph dwarf选项:
--call-graph
Setup and enable call-graph (stack chain/backtrace) recording, implies -g.
Default is "fp".
采样结果如下:
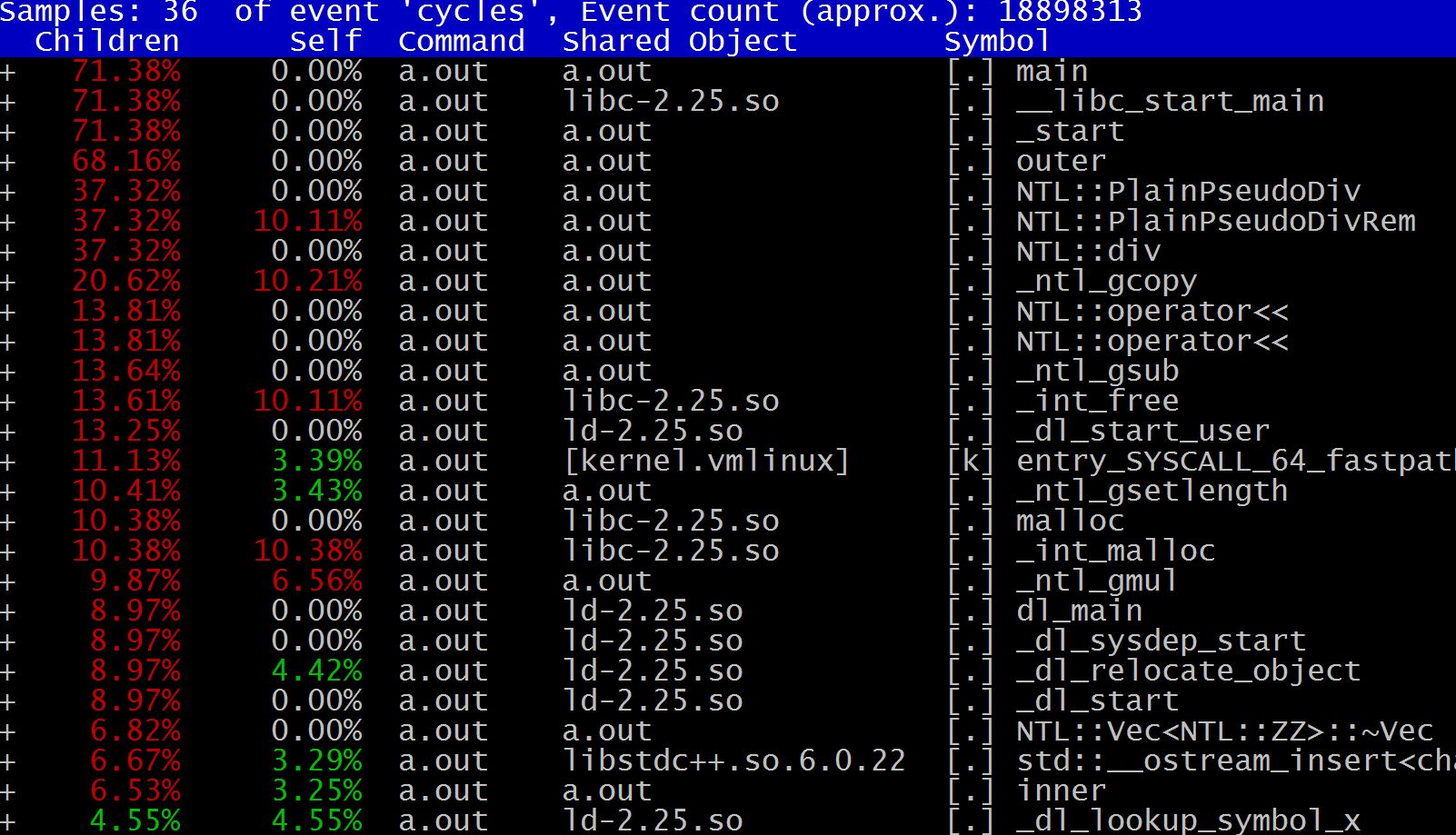
关于Children和Self的含义,perf wiki给了一个详尽的解释。以下列代码为例:
void foo(void) {
/* do something */
}
void bar(void) {
/* do something */
foo();
}
int main(void) {
bar()
return 0;
}
Self表示函数本身的overhead:如果foo函数的overhead占60%,那么bar的Self overhead就是40%(刨除foo所占部分)。因为foo和bar都是main的子函数,所以二者的overhead都要计算入main的Children overhead。
对于采用--call-graph dwarf选项生成的perf.data做出的火焰图如下:
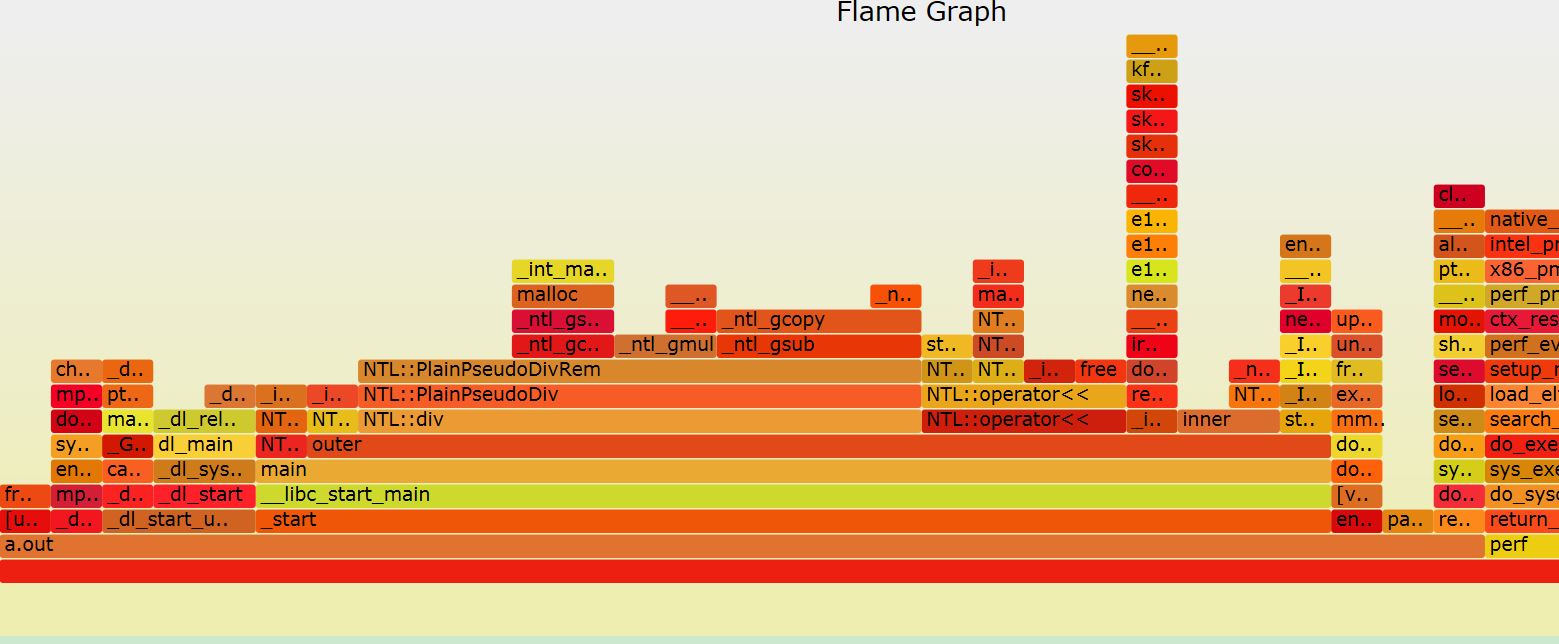 可以看到显示了完整的函数调用栈。
可以看到显示了完整的函数调用栈。
Tiptop是一个Linux系统性能工具,它通过读取CPU硬件计数器的信息(比如cahche miss,executed instructions per cycle等等),使我们对程序的执行效率有了更清晰的认识:

Tiptop通过perf_event_open(http://man7.org/linux/man-pages/man2/perfeventopen.2.html)系统调用(2.6.31版本称为perf_counter_open)来完成读取硬件计数器信息:
int perf_event_open(struct perf_event_attr *attr,
pid_t pid, int cpu, int group_fd,
unsigned long flags);
attr用来指定需要关注哪些硬件计数器;pid和cpu指定关注运行在哪些CPU的进程(线程);group_fd用来设定event group,创建group leader时,group_fd设为-1;flags可以置为0。
perf_event_open执行成功后会返回一个有效的文件描述符,后续可通过ioctl和read系统调用对这个文件描述符进行操作,达到想要的目的。
Perf_events所处理的hardware event(硬件事件)需要CPU的支持,而目前主流的CPU基本都包含了PMU(Performance Monitoring Unit,性能监控单元)。PMU用来统计性能相关的参数,像cache命中率,指令周期等等。由于这些统计工作是硬件完成的,所以CPU开销很小。
以X86体系结构为例,PMU包含了两种MSRs(Model-Specific Registers,之所以称之为Model-Specific,是因为不同model的CPU,有些register是不同的):Performance Event Select Registers和Performance Monitoring Counters(PMC)。当想对某种性能事件(performance event)进行统计时,需要对Performance Event Select Register进行设置,统计结果会存在Performance Monitoring Counter中。
当perf_events工作在采样模式(sampling,perf record命令即工作在这种模式)时,由于采样事件发生时和实际处理采样事件之间有时间上的delay,以及CPU流水线和乱序执行等因素,所以得到的指令地址IP(Instruction Pointer)并不是当时产生采样事件的IP,这个称之为skid。为了改善这种状况,使IP值更加准确,Intel使用PEBS(Precise Event-Based Sampling),而AMD则使用IBS(Instruction-Based Sampling)。
以PEBS为例:每次采样事件发生时,会先把采样数据存到一个缓冲区中(PEBS buffer),当缓冲区内容达到某一值时,再一次性处理,这样可以很好地解决skid问题。
执行一下perf list --help命令,会看到下面内容:
The p modifier can be used for specifying how precise the instruction address should be. The p modifier can be specified multiple times:
0 - SAMPLE_IP can have arbitrary skid
1 - SAMPLE_IP must have constant skid
2 - SAMPLE_IP requested to have 0 skid
3 - SAMPLE_IP must have 0 skid
For Intel systems precise event sampling is implemented with PEBS which supports up to precise-level 2.
现在可以理解,经常看到的类似“perf record -e "cpu/mem-loads/pp" -a”命令中,pp就是指定IP精度的。
Perf_events是目前在Linux上使用广泛的profiling/tracing工具,除了本身是内核(kernel)的组成部分以外,还提供了用户空间(user-space)的命令行工具(“perf”,“perf-record”,“perf-stat”等等)。
perf_events提供两种工作模式:采样模式(sampling)和计数模式(counting)。“perf record”命令工作在采样模式:周期性地做事件采样,并把信息记录下来,默认保存在perf.data文件;而“perf stat”命令工作在计数模式:仅仅统计某个事件发生的次数。
我们经常看到类似这样的命令:“perf record -a ...... sleep 10”。在这里,“sleep”这个命令相当于一个“dummy”命令,没有做任何有意义的工作,它的作用是让“perf record”命令对整个系统进行采样,并在10秒后自动结束采样工作。