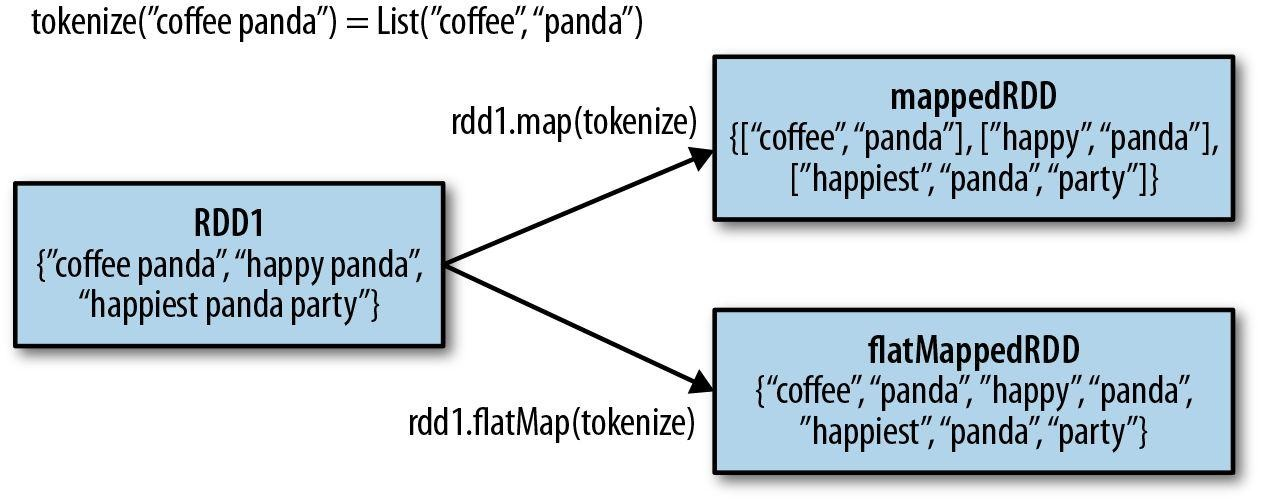
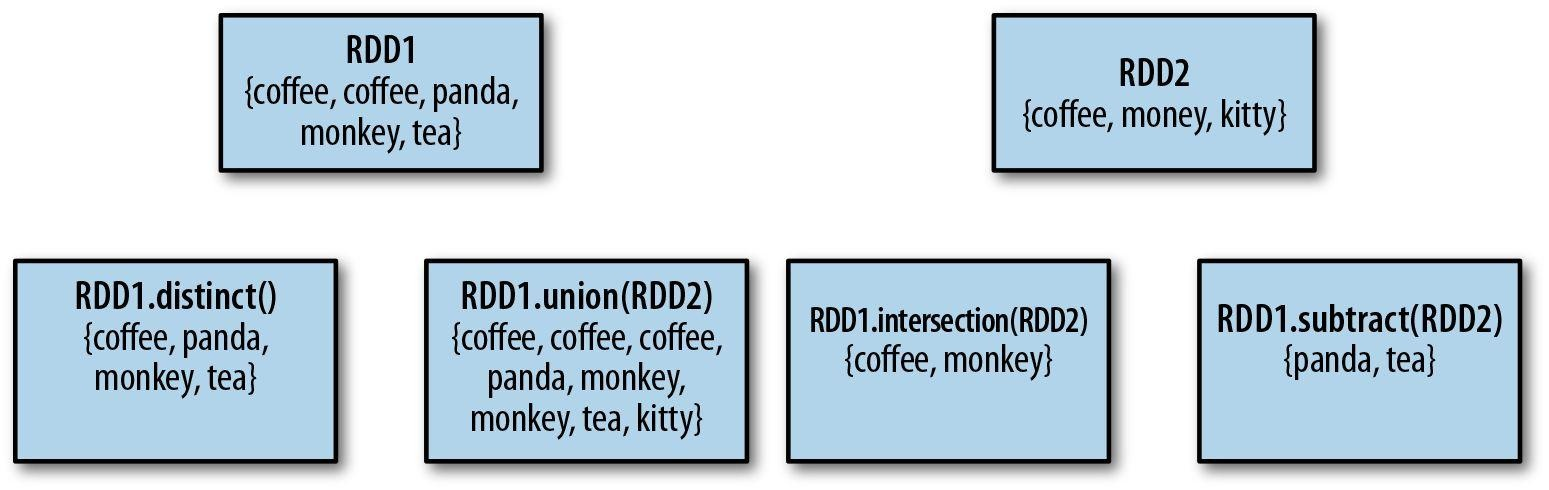
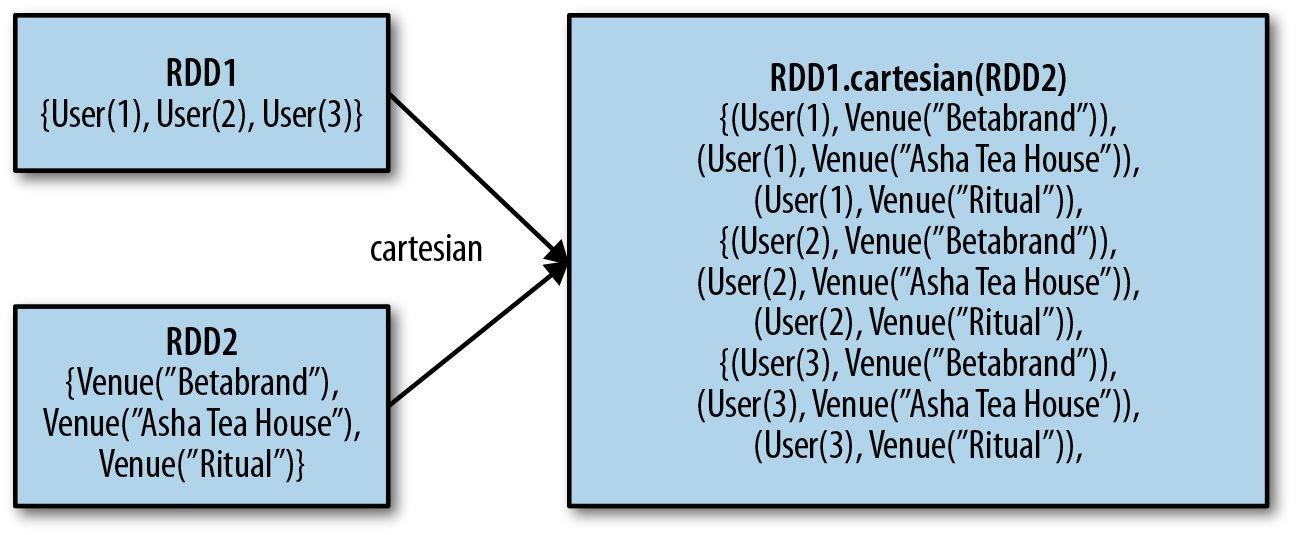
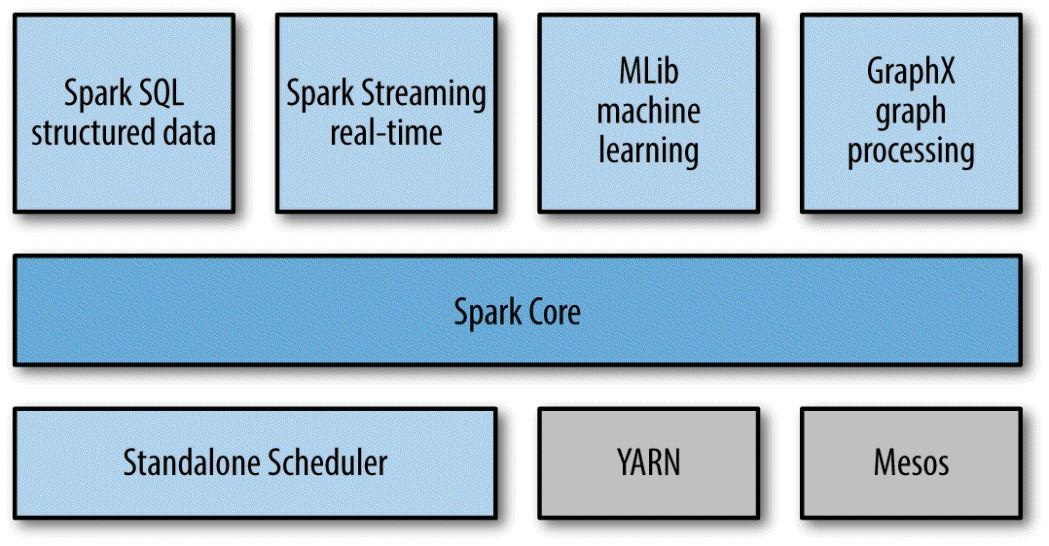
本文使用docker搭建Spark环境,使用的image文件是sequenceiq提供的1.3.0版本。
首先pull Spark image文件:
docker pull sequenceiq/spark:1.3.0
pull成功后,运行Spark:
docker run -i -t -h sandbox sequenceiq/spark:1.3.0 bash
测试Spark是否工作正常:
bash-4.1
......
scala> sc.parallelize(1 to 1000).count()
......
res0: Long = 1000
输出1000,OK!
(1)启动spark-shell,输出log很多,解决方法如下:
a)把/usr/local/spark/conf文件夹下的log4j.properties.template文件复制生成一份log4j.properties文件:
bash-4.1
bash-4.1
b)把log4j.properties文件里的“log4j.rootCategory=INFO, console”改成“log4j.rootCategory=WARN, console”即可。
(2)启动spark-shell会有以下warning:
15/05/25 04:49:28 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
提示找不到hadoop的库文件,解决办法如下:
export LD_LIBRARY_PATH=/usr/local/hadoop/lib/native/:$LD_LIBRARY_PATH
请参考stackoverflow的相关讨论:
a)Hadoop “Unable to load native-hadoop library for your platform” error on CentOS;
b)Hadoop “Unable to load native-hadoop library for your platform” error on docker-spark?。
(3)在Quick Start中提到如下例子:
scala> val textFile = sc.textFile("README.md")
......
scala> textFile.count() // Number of items in this RDD
执行会有错误:
scala> textFile.count()
org.apache.hadoop.mapred.InvalidInputException: Input path does not exist: hdfs://sandbox:9000/user/root/README.md
at org.apache.hadoop.mapred.FileInputFormat.singleThreadedListStatus(FileInputFormat.java:285)
at org.apache.hadoop.mapred.FileInputFormat.listStatus(FileInputFormat.java:228)
at org.apache.hadoop.mapred.FileInputFormat.getSplits(FileInputFormat.java:304)
at org.apache.spark.rdd.HadoopRDD.getPartitions(HadoopRDD.scala:203)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:219)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:217)
at scala.Option.getOrElse(Option.scala:120)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:217)
可以看到程序尝试从hdfs中寻找文件,所以报错。
解决方法有两种:
a) 指定本地文件系统:
scala> val textFile = sc.textFile("file:///usr/local/spark/README.md")
textFile: org.apache.spark.rdd.RDD[String] = file:
scala> textFile.count()
res1: Long = 98
b)上传文件到hdfs上:
bash-4.1
接着运行spark-shell:
bash-4.1# spark-shell
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.3.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_51)
Type in expressions to have them evaluated.
Type :help for more information.
15/05/25 05:22:15 WARN Client: SPARK_JAR detected in the system environment. This variable has been deprecated in favor of the spark.yarn.jar configuration variable.
15/05/25 05:22:15 WARN Client: SPARK_JAR detected in the system environment. This variable has been deprecated in favor of the spark.yarn.jar configuration variable.
Spark context available as sc.
SQL context available as sqlContext.
scala> val textFile = sc.textFile("README.md")
textFile: org.apache.spark.rdd.RDD[String] = README.md MapPartitionsRDD[1] at textFile at <console>:21
scala> textFile.count()
res0: Long = 98
参考邮件:
Spark Quick Start – call to open README.md needs explicit fs prefix。
P.S.在主机(非docker环境)下载spark(https://spark.apache.org/downloads.html)运行时,会有以下warning:
log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html
解决办法是把/path/to/spark/conf文件夹下的log4j.properties.template文件复制生成一份log4j.properties文件即可。
参考stackoverflow的讨论:
log4j:WARN No appenders could be found for logger (running jar file, not web app)。