本文介绍的转换(transformation)运算适用于所有类型的RDD。
Element-wise转换:
在Spark中,最常用的的转换运算是map()和filter()。map()运算会对RDD中的每个元素进行函数运算,而filter()运算只会作用于RDD中符合过滤条件的元素,运算结果生成一个新的RDD。看下面这个例子:

需要注意的是map()运算的结果类型不一定要同输入类型一致。
有时需要从一个输入元素生成多个输出元素,这时可以使用flatMap()运算。同map()一样,flatMap()
也会对输入RDD中的每个元素进行运算,但运算结果是一个包含返回值的迭代器(iterator)。最终产生的RDD会包含所有迭代器中的元素。但要注意的是,这个RDD的元素数据类型并不是迭代器,而是迭代器所包含的元素的数据类型。flatMap()和map()的区别可以用下图来理解
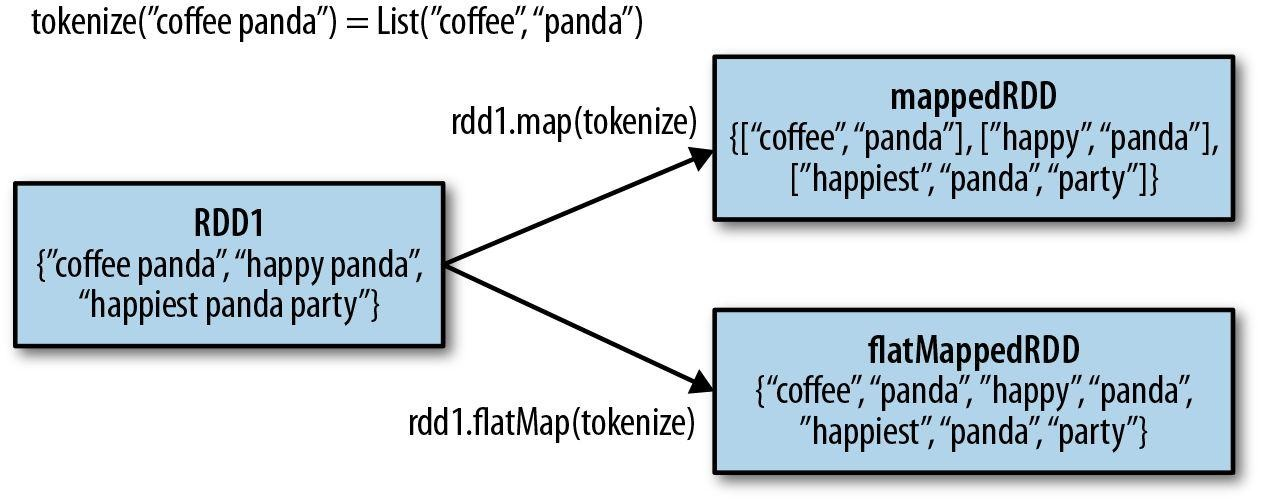
可以认为flat的含义就是“铲平”迭代器,把里面的元素“拿”出来,生成一个新的RDD。
伪集合运算(Pseudo set operations):
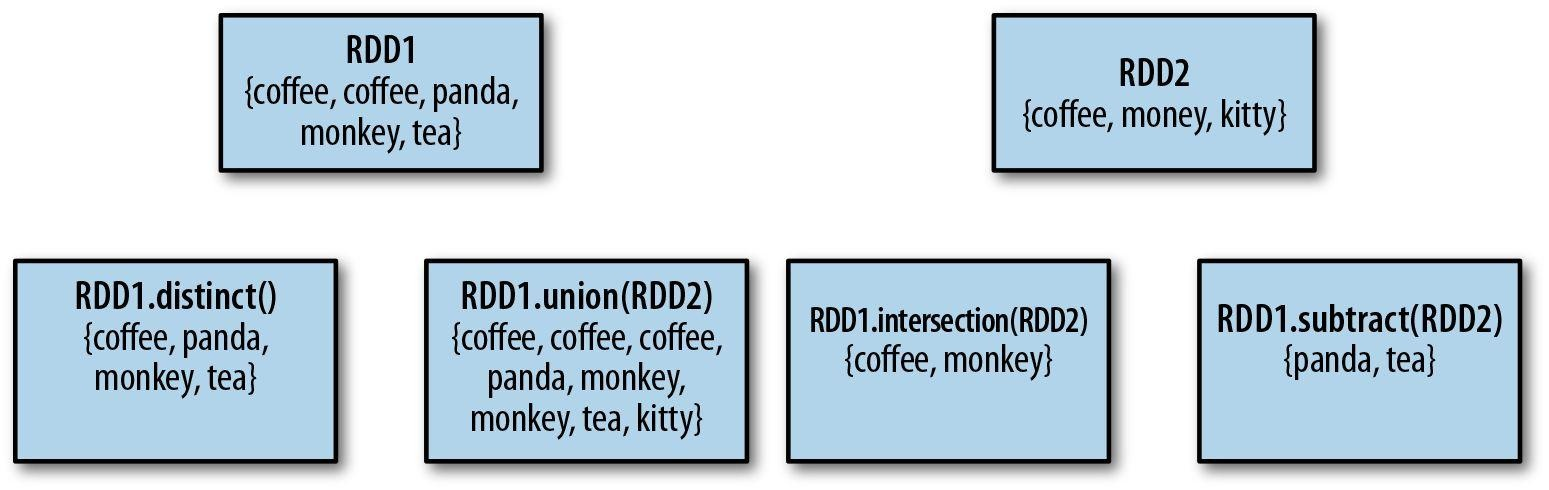
RDD支持很多类似数学里的集合运算:取“交集”,“并集”等等。需要注意的是,进行运算的这些RDD必须具有相同的数据类型。下图展示了一些运算:
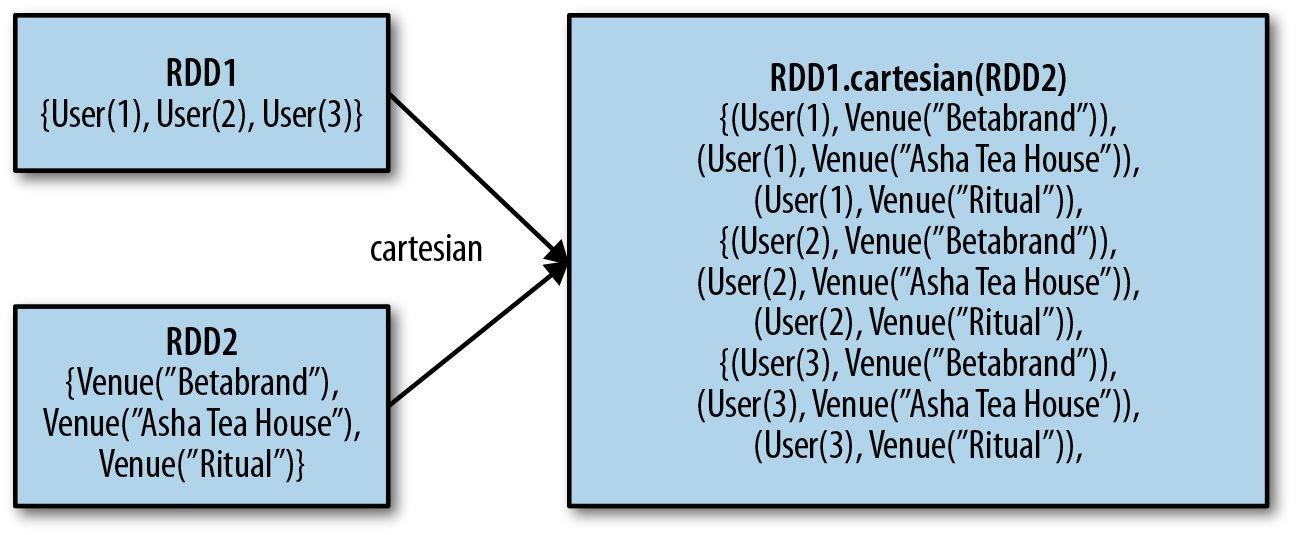
两个RDD之间还可以进行笛卡尔积运算: