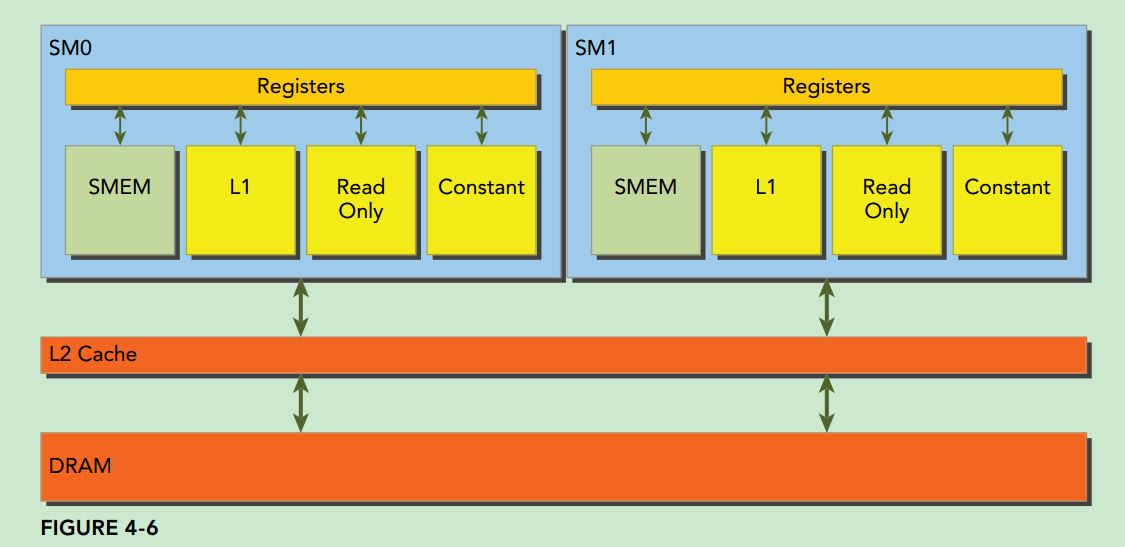
nvcc是“The main wrapper for the NVIDIA CUDA Compiler suite. Used to compile and link both host and gpu code.”,查看其版本可以使用--version选项:
$ nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2016 NVIDIA Corporation
Built on Sun_Sep__4_22:14:01_CDT_2016
Cuda compilation tools, release 8.0, V8.0.44
关于不同CUDA版本所支持的compute capability可以参考这里:
CUDA VERSION Min CC Deprecated CC Default CC
5.5 (and prior) 1.0 N/A 1.0
6.0 1.0 1.0 1.0
6.5 1.1 1.x 2.0
7.0 2.0 N/A 2.0
7.5 (same as 7.0)
8.0 2.0 2.x 2.0
Min CC = minimum compute capability that can be specified to nvcc
Deprecated CC = If you specify this CC, you will get a deprecation message, but compile should still proceed.
Default CC = The architecture that will be targetted if no `-arch` or `-gencode` switches are used
根据CUDA命名规范:GPUs are named sm_xy, where x denotes the GPU generation number, and y the version in that generation.。
This situation is different for GPUs, because NVIDIA cannot guarantee binary compatibility without sacrificing regular opportunities for GPU improvements. Rather, as is already conventional in the graphics programming domain, nvcc relies on a two stage compilation model for ensuring application compatibility with future GPU generations.
nvcc可以保证编译出程序的application compatibility,但不能保证binary compatibility。在编译过程中,第一阶段产生virtual GPU architecture code,即PTX;第二阶段才编译出在真实GPU上运行的代码。因此真实的GPU必须实现了virtual GPU所要求的功能。因此,From this it follows that the virtual architecture should always be chosen as low as possible, thereby maximizing the actual GPUs to run on. The real architecture should be chosen as high as possible (assuming that this always generates better code), but this is only possible with knowledge of the actual GPUs on which the application is expected to run.。
--gpu-architecture arch编译选项用来指定NVIDIA virtual GPU architecture。例如,compute_50。通常情况下,--gpu-architecture arch是用来生成PTX代码,不会用来生成运行在特定GPU上的代码。--gpu-code code,...选项则是用来指定the name of the NVIDIA GPU to assemble and optimize PTX for。例如,sm_50。关于这两个选项的取值的例子,可以参考这里。
参考资料:
NVIDIA CUDA Compiler Driver NVCC;
What is the purpose of using multiple “arch” flags in Nvidia’s NVCC compiler?。