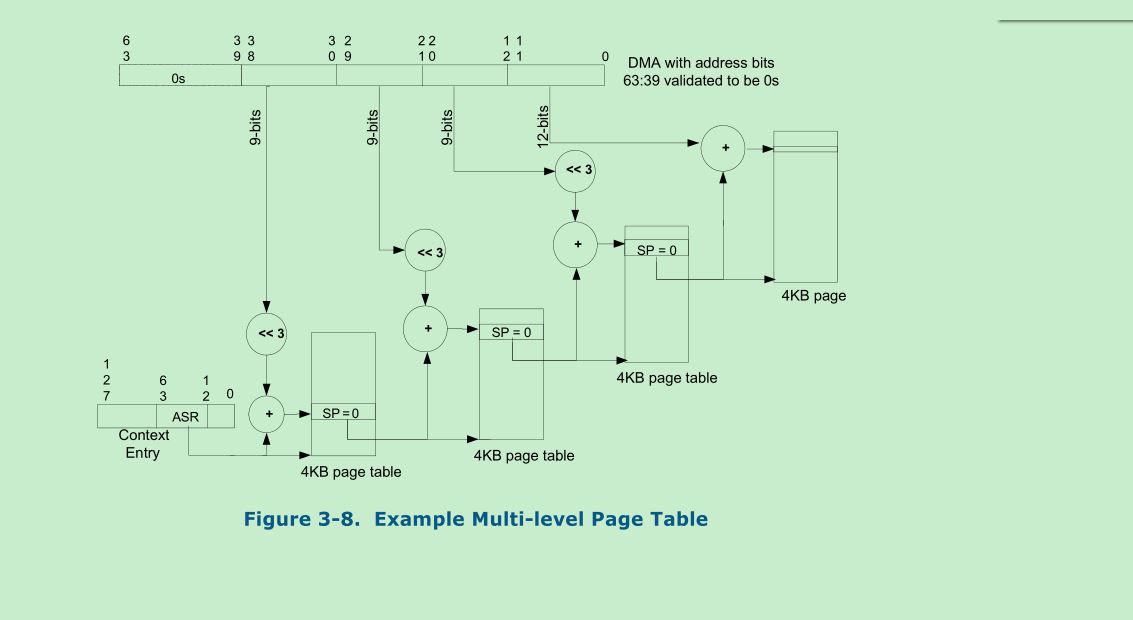
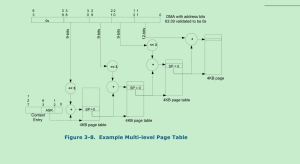
DMA请求的地址转换如下图所示:
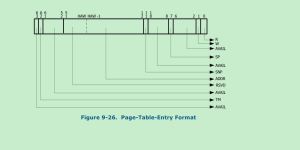
page-table entry格式如下:
因为每个page-table entry占8(2^3)个byte,所以上面的转化图中只要9位就可以了(12 - 3,2^12 = 4KiB)。
GAW的定义:
Guest Address Width: Physical addressability limit within a partition (virtual machine)
可以理解为从虚拟机角度看到的物理地址宽度。举个例子,如果一个虚拟机只能访问2G内存,那么GAW就是31。
AGAW的定义:Adjusted Guest Address Width。为了保证9个bit长度的步长转化,GAW和AGAW之间的转换伪代码如下:
R = (GAW - 12) MOD 9;
if (R == 0) {
AGAW = GAW;
} else {
AGAW = GAW + 9 - R;
}
if (AGAW > 64)
AGAW = 64;
对应的函数是guestwidth_to_adjustwidth:
static inline int guestwidth_to_adjustwidth(int gaw)
{
int agaw;
int r = (gaw - 12) % 9;
if (r == 0)
agaw = gaw;
else
agaw = gaw + 9 - r;
if (agaw > 64)
agaw = 64;
return agaw;
}
AGAW的最小长度是30个bit,参考以下规范定义(context-entry格式里的内容):
• 000b: 30-bit AGAW (2-level page table)
• 001b: 39-bit AGAW (3-level page table)
• 010b: 48-bit AGAW (4-level page table)
• 011b: 57-bit AGAW (5-level page table)
• 100b: 64-bit AGAW (6-level page table)
所以可以看到kernel里agaw的一些转换代码会用到30和2这些数字:
static inline int agaw_to_level(int agaw)
{
return agaw + 2;
}
static inline int agaw_to_width(int agaw)
{
return min_t(int, 30 + agaw * LEVEL_STRIDE, MAX_AGAW_WIDTH);
}
static inline int width_to_agaw(int width)
{
return DIV_ROUND_UP(width - 30, LEVEL_STRIDE);
}