前几天网上出现了Solaris项目将会被Oracle停掉的谣言。尽管消息一直未被证实,但是以Solaris为代表的传统Unix操作系统的没落却是不争的事实。在上个月,top500发布的目前世界上运行最快的500台超级计算机中,有498台运行的是Linux:
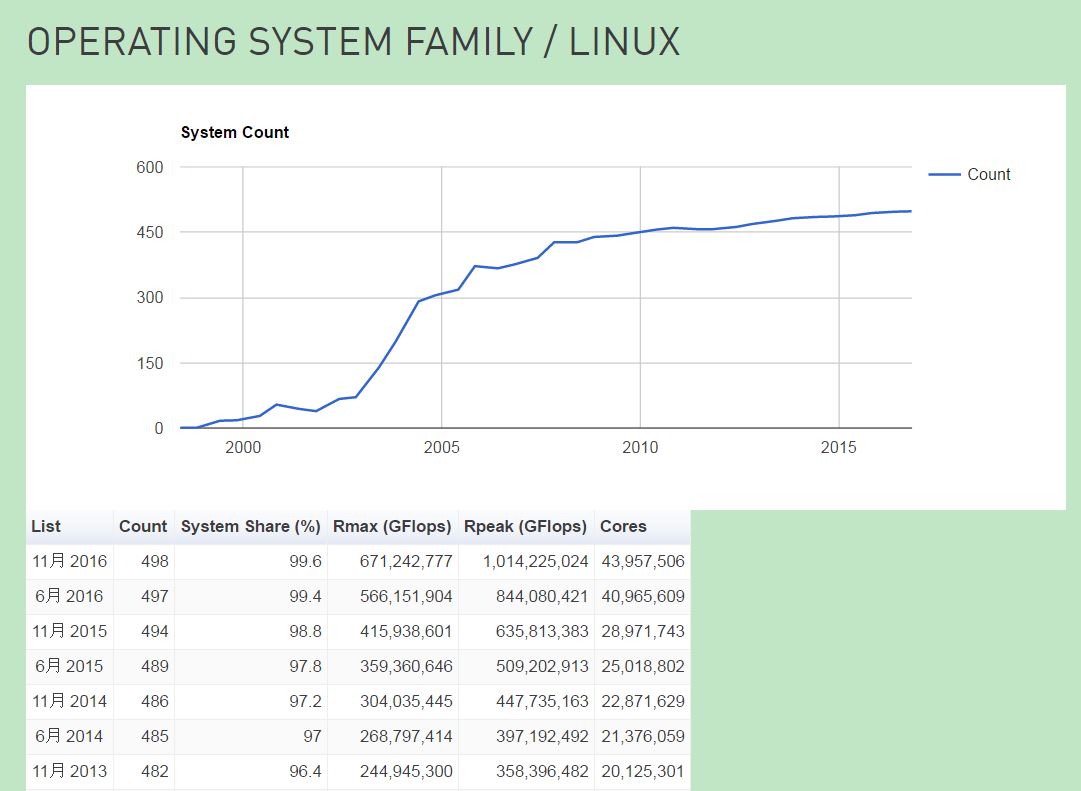
由此可见,Linux与Unix目前的境遇可谓是天壤之别。
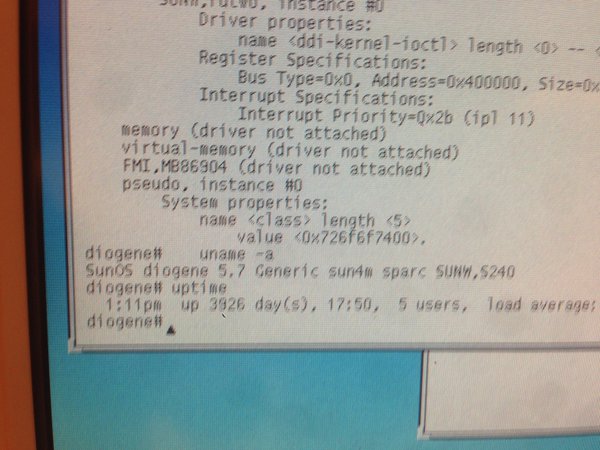
我不知道究竟是什么原因造成了目前Linux一统天下的局面,但是可以确定的是一定不是技术领域方面的原因。我没有为IBM公司工作过,也从未接触过AIX操作系统,所以对AIX没有发言权。而对于BSD系列操作系统(FreeBSD,OpenBSD,NetBSD等等),仅仅限于安装和使用过,并没有什么太深的体会。我为HP/HPE公司效力过,虽然并没有使用过HP-UX,但是周围有很多同事以前是做HP-UX相关工作的:开发新功能,做Unix认证等等。听他们讲,HP-UX非常稳定,很多电信,银行等对稳定性要求特别高的环境仍然在使用着HP-UX,也许这些企业慢慢地会转向Linux?我不知道。。。至于Solaris,我曾经在上面做过4年多的全职开发。Solaris上面有很多很cool的工具供用户使用,比如mdb,比如DTrace,这些工具为我工作提供了巨大的帮助,极大地满足了一个底层软件工程师的好奇心。此外Solaris也是以运行稳定而著称,比如这台已经连续运行了10年的装有Solaris的机器(图片出处:https://pbs.twimg.com/media/CjtxiOmWYAA5lHB.jpg):
再来看看Linux,其实一直以来,Linux系统上并没有可以匹敌DTrace的系统tracing工具,直至最近BPF功能的成熟,可以说在tracing领域落后了Solaris整整12年(可以参考这篇文章:Linux in 2016 catches up to Solaris from 2004);再比如目前Ubuntu发行版中引入的ZFS文件系统,也是出自Solaris。所以,其实如果单单从技术领域来看,Linux不仅不见得做的比Unix好,某些方面甚至还是处于下风的。
在上面提到的几种Unix中,除了BSD系列,其余3种可以说都是某个传统硬件服务器厂商的私有操作系统。虽然曾经有OpenSolaris这个开源产品,但是也仅仅是昙花一现(个人觉得OpenSolaris最大的意义在于由其衍生出了illumos内核,以及基于illumos内核的类Solaris系统。比如smartos。)。所以说,是不是由于最近这些年互联网的日渐强势,硬件厂商的效益江河日下,而“城门失火,殃及池鱼”,随之而来的就是这些Unix也会受到不小的冲击呢?个人觉得应该有一定关系吧。但如果仅仅把Linux成功的原因归结于“开源”,似乎也有失偏颇,BSD系列操作系统也是开源的,且其在license上更为宽松(参考这里:Comparing BSD and Linux)。所以说对于Linux目前具有如此统治力的原因,真的是很难说清。
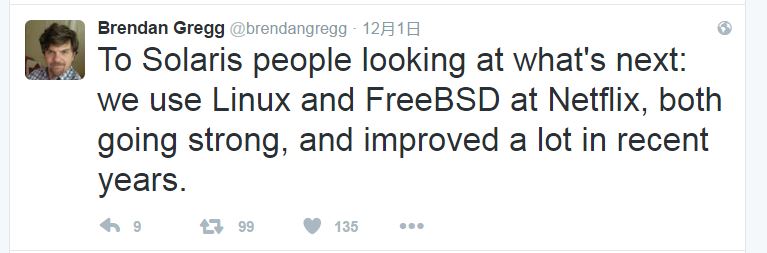
相信目前很多的中小公司都完全转向Linux了。最直白的原因:人好招。你见过多少招聘信息要求熟悉FreeBSD?肯定没有要求Linux的多。至于要求熟悉NetBSD的?也许有,但是我是没见过。所以对目前Unix人才的需要还是主要在大公司,也只有大公司有意愿和实力做这些“日渐小众”的Unix的相关工作。例如,Brendan Gregg在其社交账号中为对Solaris工程师提到Netflix目前使用FreeBSD:
我很怀念十几年前各大操作系统“百花齐放”的时代,这样想并不是因为我对Linux有任何成见,只是当你的服务器都运行着清一色的Linux操作系统时,实在是觉得有些单调和乏味,就像现在人类使用的手机也基本可以分为两大阵营:iOS和Android(又是Linux)。世界本应该就是多样化的,丰富多彩的,所以希望其它的Unix有朝一日可以“复兴”吧。。。