libvirt提供了一个用来管理虚拟机的抽象层。它包含如下部分:一组C API;各种编程语言的绑定;一个daemon进程(libvirtd)和一个命令行工具(virsh)。结构如下图所示:

virt-manager是一个管理虚拟机的图形化工具,它类似于VirtualBox。另外,virt-manager还提供了virt-clone等命令行工具。
libvirt提供了一个用来管理虚拟机的抽象层。它包含如下部分:一组C API;各种编程语言的绑定;一个daemon进程(libvirtd)和一个命令行工具(virsh)。结构如下图所示:
virt-manager是一个管理虚拟机的图形化工具,它类似于VirtualBox。另外,virt-manager还提供了virt-clone等命令行工具。
(1)Binary writing
Binary writing has the nice benefit that it allows most of the virtual environment to run in userspace, but imposes a performance penalty.
The binary rewriting approach requires that the instruction stream be scanned by the virtualization environment and privileged instructions identified. These are then rewritten to point to their emulated versions.
Binary writing的核心之处在于把privileged instructions重写。
(2)Paravirtualization
Rather than dealing with problematic instructions, paravirtualization systems like Xen simply ignore them.
If a guest system executes an instruction that doesn’t trap while inside a paravirtualized environment, then the guest has to deal with the consequences. Conceptually, this is similar to the binary rewriting approach, except that the rewriting happens at compile time (or design time), rather than at runtime.
The environment presented to a Xen guest is not quite the same as that of a real x86 system. It is sufficiently similar, however, in that it is usually a fairly simple task to port an operating system to Xen.
From the perspective of an operating system, the biggest difference is that it runs in ring 1 on a Xen system, instead of ring 0. This means that it cannot perform any privileged instructions. In order to provide similar functionality, the hypervisor exposes a set of hypercalls that correspond to the instructions.
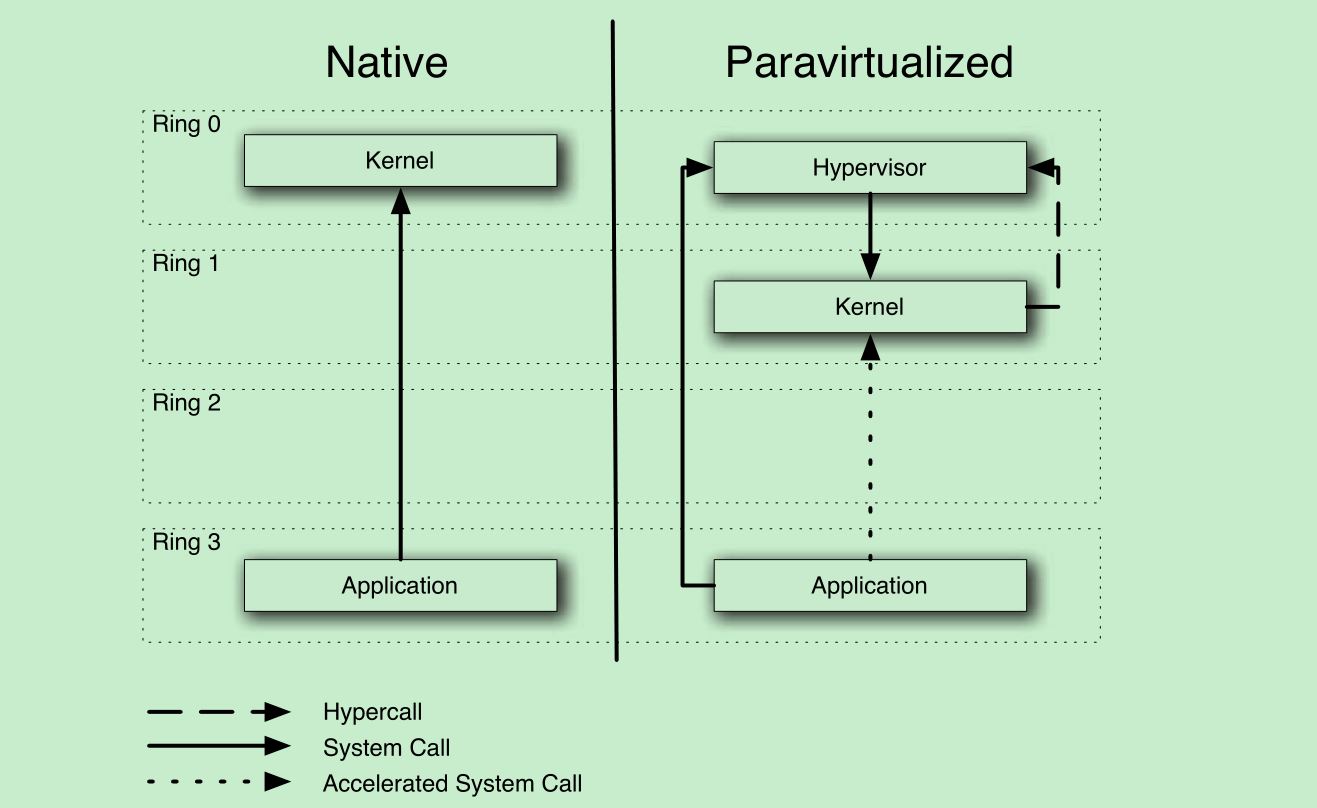
Paravirtualization核心之处在于hypervisor提供hypercalls给Guest OS,以弥补其不能使用privileged instructions。
(3)Hardware-Assisted Virtualization
Now, both Intel and AMD have added a set of instructions that makes virtualization considerably easier for x86. AMD introduced AMD-V, formerly known as Pacifica, whereas Intel’s extensions are known simply as (Intel) Virtualization Technology (IVT or VT). The idea behind these is to extend the x86 ISA to make up for the shortcomings in the existing instruction set. Conceptually, they can be thought of as adding a “ring -1” above ring 0, allowing the OS to stay where it expects to be and catching attempts to access the hardware directly. In implementation, more than one ring is added, but the important thing is that there is an extra privilege mode where a hypervisor can trap and emulate operations that would previously have silently failed.
IVT adds a new mode to the processor, called VMX. A hypervisor can run in VMX mode and be invisible to the operating system, running in ring 0. When the CPU is in VMX mode, it looks normal from the perspective of an unmodified OS. All instructions do what they would be expected to, from the perspective of the guest, and there are no unexpected failures as long as the hypervisor correctly performs the emulation.
A set of extra instructions is added that can be used by a process in VMX root mode. These instructions do things like allocating a memory page on which to store a full copy of the CPU state, start, and stop a VM. Finally, a set of bitmaps is defined indicating whether a particular interrupt, instruction, or exception should be passed to the virtual machine’s OS running in ring 0 or by the hypervisor running in VMX root mode.
Hardware-Assisted Virtualization(也称之为HVM,Hardware Virtual Machine),可以运行unmodified OS,其核心之处在于CPU层面提供了新的privilege mode和指令集来支持虚拟化。
Xen的虚拟化环境结构如下图所示:

Xen hypervisor:直接运行在硬件上,它负责CPU调度和为虚拟机划分内存。 Xen hypervisor不光为运行之上的虚拟机抽象出硬件,还会控制虚拟机的运行。
Domain 0:Xen hypervisor启动的第一个,拥有特权的虚拟机:比如可以直接访问硬件,启动其它虚拟机等。
Domain U:其它无特权的虚拟机,可以为PV或HM Guest。
以支持Xen的Suse为例,/boot/grub/menu.lst文件如下:
title Xen -- SUSE Linux Enterprise Server 11 SP4 - 3.0.101-63
root (hd0,1)
kernel /boot/xen.gz vga=mode-0x314
module /boot/vmlinuz-3.0.101-63-xen root=/dev/disk/by-id/ata-VBOX_HARDDISK_VBe358a50a-9595120d-part2 resume=/dev/disk/by-id/ata-VBOX_HARDDISK_VBe358a50a-9595120d-part1 splash=silent showopts vga=0x314
module /boot/initrd-3.0.101-63-xen
可以看到,实际运行的kernel是/boot/xen.gz,修改过的kernel(有-xen后缀)和initial ramdisk都是/boot/xen.gz的模块。
参考资料:
How does Xen work?;
“Emulation”是软件模拟硬件,即在你当前的host机器(举个例子:X86)上运行另一个SPARC平台的的虚拟机。软件需要把SPARC平台指令转化为X86指令,所以速度很慢。(qemu-system-x86_64)
“Hardware virtualization”是硬件支持虚拟化。即软件直接利用CPU和芯片组等硬件。由于没有指令转化,所以速度很快。当然,host机器和虚拟机是同样的指令集。(qemu-system-x86_64 -enable-kvm)
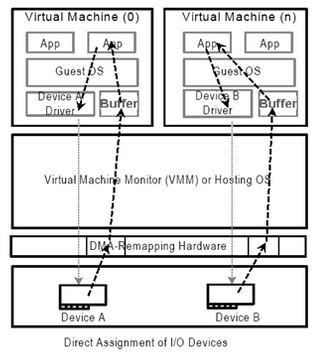
Domain是平台上一个抽象的隔离环境,并且被分配了一块主机物理内存。I/O设备作为domain的指定设备(assigned device),可以访问分配给domain的内存。在虚拟化环境下,每个虚拟机都会被当做一个独立的domain。
I/O设备分配到指定的domain,并只能访问指定domain所拥有的物理资源。依赖于具体的软件模型,DMA请求的地址可以是虚拟机,也就是domain的Guest-Physical Address(GPA),或是由PASID指定进程定义的application Virtual Address(VA),或是由软件定义的抽象的I/O virtual address(IOVA)。不管哪种情况,DMA Remapping硬件都是把相应的地址翻译成Host-Physical Address(HPA)。
KVM(Kernel-based Virtual Machine)是Linux为X86平台提供的完整虚拟化(virtualization) 解决方案,这个方案包括了虚拟化扩展(Intel VT或AMD-V)。KVM提供了一个包含虚拟化核心功能可加载的内核模块:kvm.ko,另外还有和处理器相关的模块:kvm-intel.ko和kvm-amd.ko。
利用KVM,你可以创建多个运行Linux或Windows的虚拟机,每个虚拟机都有自己私有的虚拟硬件:网卡,磁盘,等等。
KVM用户空间的组件被包含进入了QEMU的主线。
参考资料:
Kernel Virtual Machine。
Remapping硬件把来自设备的DMA内存访问请求分成两种类型:
(1)Requests without address-space-identifier:这是来自endpoint device的正常的内存访问请求,包括访问类型(读,写,原子访问),DMA地址和大小,发起请求的设备标示;
(2)Requests with address-space-identifier:这种内存访问请求会包含额外的信息:表明支持virtual memory的endpoint device的targeted process address space。除了常规请求信息外,还有process address space identifier (PASID),扩展属性:Execute-Requested (ER) flag、
(to indicate reads that are instruction fetches)Privileged-mode-Requested (PR) flag (to distinguish user versus supervisor access))等等。
“Intel VT-d(以下简称VT-d)”代表“Intel Virtualization Technology for Directed I/O”。“VT(Virtualization Technology)”泛指Intel所有的虚拟化技术,而“VT-d”则是虚拟化技术解决方案中的一种。VT-d的整体思想就是用硬件方式支持隔离和限制对设备的访问。
VT-d有以下主要功能:
a)分配I/O设备:这个功能允许管理员根据需求,灵活地为虚拟机分配I/O设备。
b)DMA remapping:支持针对虚拟机DMA访问的地址转换。
c)Interrupt remapping:支持虚拟机对设备中断的路由和隔离。
d)可靠性功能:记录关于DMA和Interrupt的错误访问。
参考资料:
Understanding VT-d: Intel Virtualization Technology for Directed I/O。
DMA(Direct Nemory Access) Remapping是一种用来限制硬件设备只能使用DMA访问预先分配的内存区域(domain or physical memory regions)的技术。DMA Remapping会把DMA请求里的地址转化成正确的物理内存地址,同时还会检查设备是否允许访问指定的内存。请看下图:
虚拟机的操作系统(Guest OS)所提供的物理地址称为Guest Physical Address (GPA) ,它不一定与实际的物理地址一致,也就是Host Physical Address (HPA),而DMA技术则要求访问真实的物理地址。DMA Remapping技术可以把Guest OS提供的GPA转化成HPA,然后数据就可以直接发送到Guest OS的缓冲区(buffer)了。
主机平台(host platform)可以支持一个或多个DMA remapping硬件单元(hardware unit),每个硬件单元remapping从它控制的作用域内发出的DMA remapping请求。主机固件(BIOS)需要把每个DMA remapping硬件单元报给系统软件(比如操作系统)。
DMA remapping硬件单元使用source-id来标示发出DMA请求的设备。对一个PCI Express设备,source-id就是resource identifier:
________________________________________________________
|____Bus(8 bits)_________|__Device(5 bits)|_func(3 bits)_|
Root-entry作为最顶层的数据结构,会把某特定PCI总线上的设备映射到对应的domain。一个context-entry会把一个地址总线上的某个具体设备映射到对应的domain。参考下图:
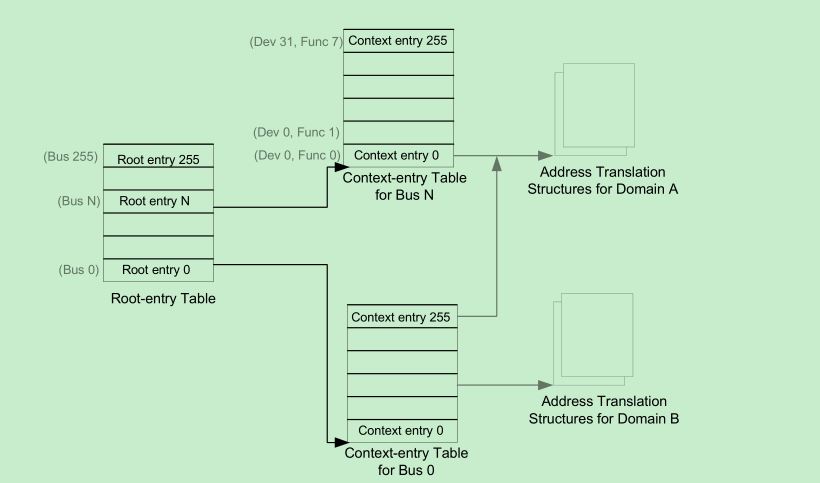
每个root-entry会有一个指向一个context-entry的表的指针,而每个context-entry则会包含如何用来进行地址转化的结构。
在计算机领域,IOMMU(Input/Output Memory Management Unit)是一个内存管理单元(Memory Management Unit),它的作用是连接DMA-capable I/O总线(Direct Memory Access-capable I/O Bus)和主存(main memory)。传统的内存管理单元会把CPU访问的虚拟地址转化成实际的物理地址。而IOMMU则是把设备(device)访问的虚拟地址转化成物理地址。为了防止设备错误地访问内存,有些IOMMU还提供了访问内存保护机制。参考下图:
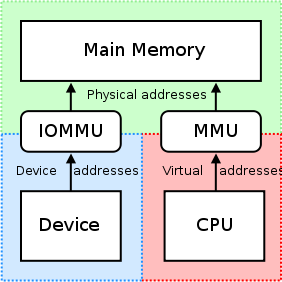
IOMMU的一个重要用途是在虚拟化技术(virtualization):虚拟机上运行的操作系统(guest OS)通常不知道它所访问的host-physical内存地址。如果要进行DMA操作,就有可能破坏内存,因为实际的硬件(hardware)不知道guest-physical和host-physical内存地址之间的映射关系。IOMMU根据guest-physical和host-physical内存地址之间的转换表(translation table),re-mapping硬件访问的地址,就可以解决这个问题。
另外,在AMD的VIRTUALIZING IO THROUGH THE IO MEMORY MANAGEMENT UNIT (IOMMU)文档中,也有一个更全面的总结图:

参考资料:
IOMMU。