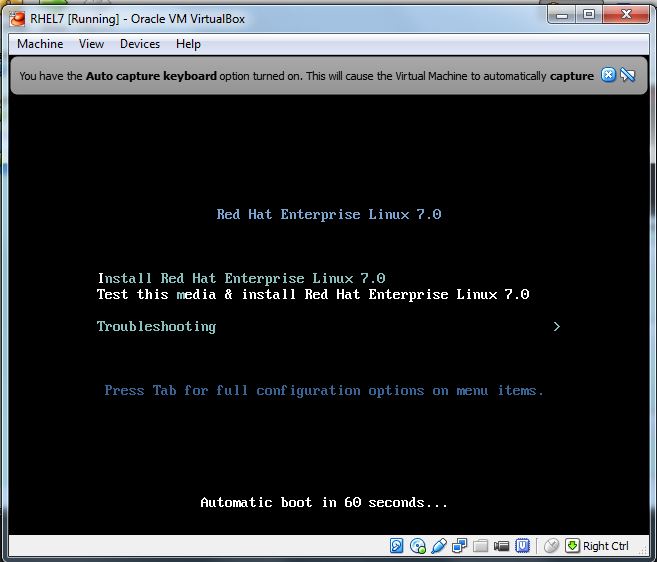
(1) In the following screen, press ESC key:
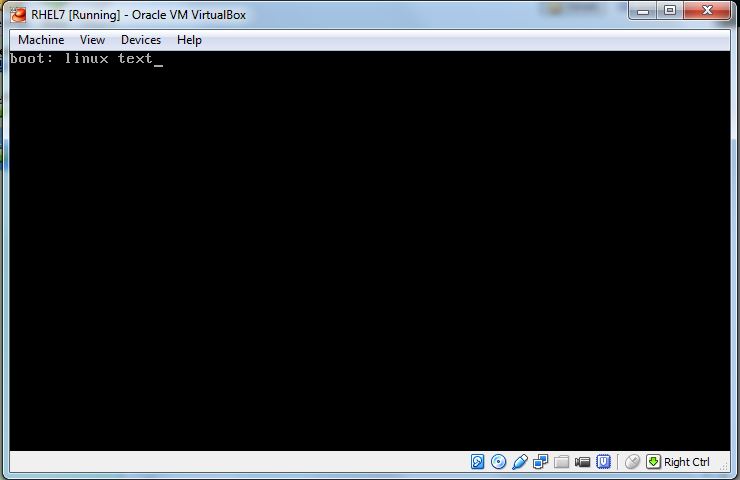
(2) In the following screen, input “linux text“, then press ENTER key:
(3) The screen is like this:
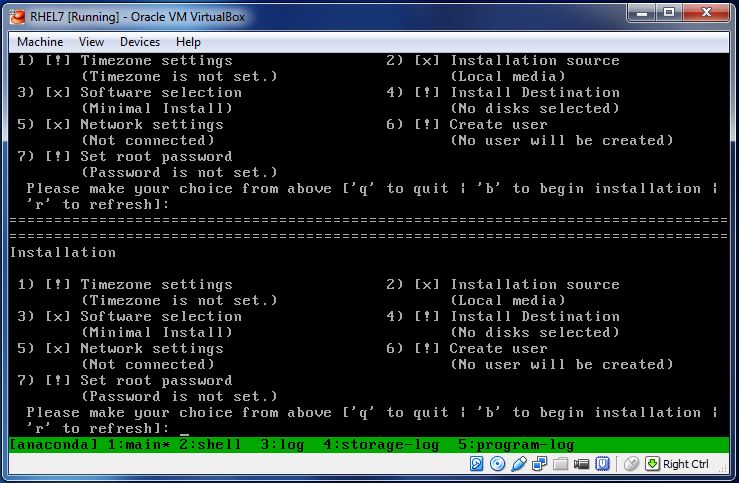
you can follow the instructions to install OS now.
(1) In the following screen, press ESC key:
(2) In the following screen, input “linux text“, then press ENTER key:
(3) The screen is like this:
you can follow the instructions to install OS now.
On RHEL 7.0, if mountRHEL 7.1 iso and install RPM package, rpm command will complain:
[root@root Packages]# rpm -ivh xxxx.x86_64.rpm
error: xxxx.x86_64.rpm: not an rpm package (or package manifest):
So you should mount RHEL 7.0 iso, then all is OK。
Execute “make menuconfig” command, then select “General setup” -> “Local version - append to kernel release“. Add you preferred name, e.g.: “.nan“, then save it.
Check if it is saved in .config file successfully:
[root@linux]# grep -i ".nan" .config
CONFIG_LOCALVERSION=".nan"
After making sure it is saved successfully, you can execute “make” command.
Using “tar -Jxvf *.tar.xz” command can decompress “*.tar.xz” file. E.g.:
[root@localhost ~]# wget https://www.kernel.org/pub/linux/kernel/v4.x/testing/linux-4.2-rc3.tar.xz
[root@localhost ~]# tar -Jxvf linux-4.2-rc3.tar.xzWhen using “http” package in golang, you should use the full domain name, For example:
package main
import (
"net/http"
"fmt"
"io/ioutil"
"os"
)
func main() {
resp, err := http.Get("www.google.com")
if err != nil {
fmt.Println(err)
os.Exit(1)
}
text, err := ioutil.ReadAll(resp.Body)
if err != nil {
fmt.Println(err)
os.Exit(1)
}
fmt.Println(string(text))
}
Executing it, the error will be:
Get www.google.com: unsupported protocol scheme ""
Add “http://” before “www.google.com“, then executing it. The result is OK:
<!doctype html><html itemscope="" itemtype="http://schema.org/WebPage" lang="en"><head><meta co.... P.S., the full code is here.