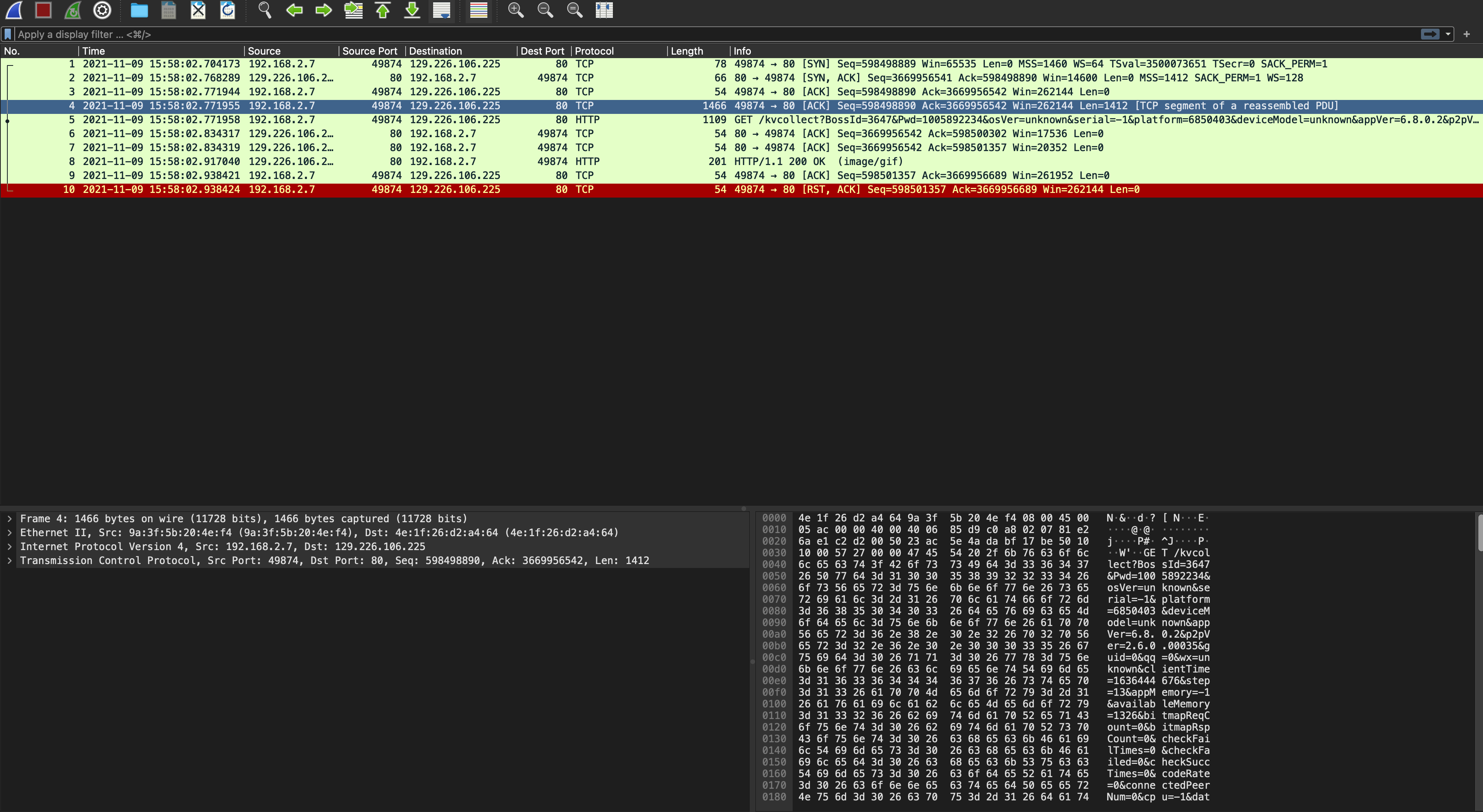
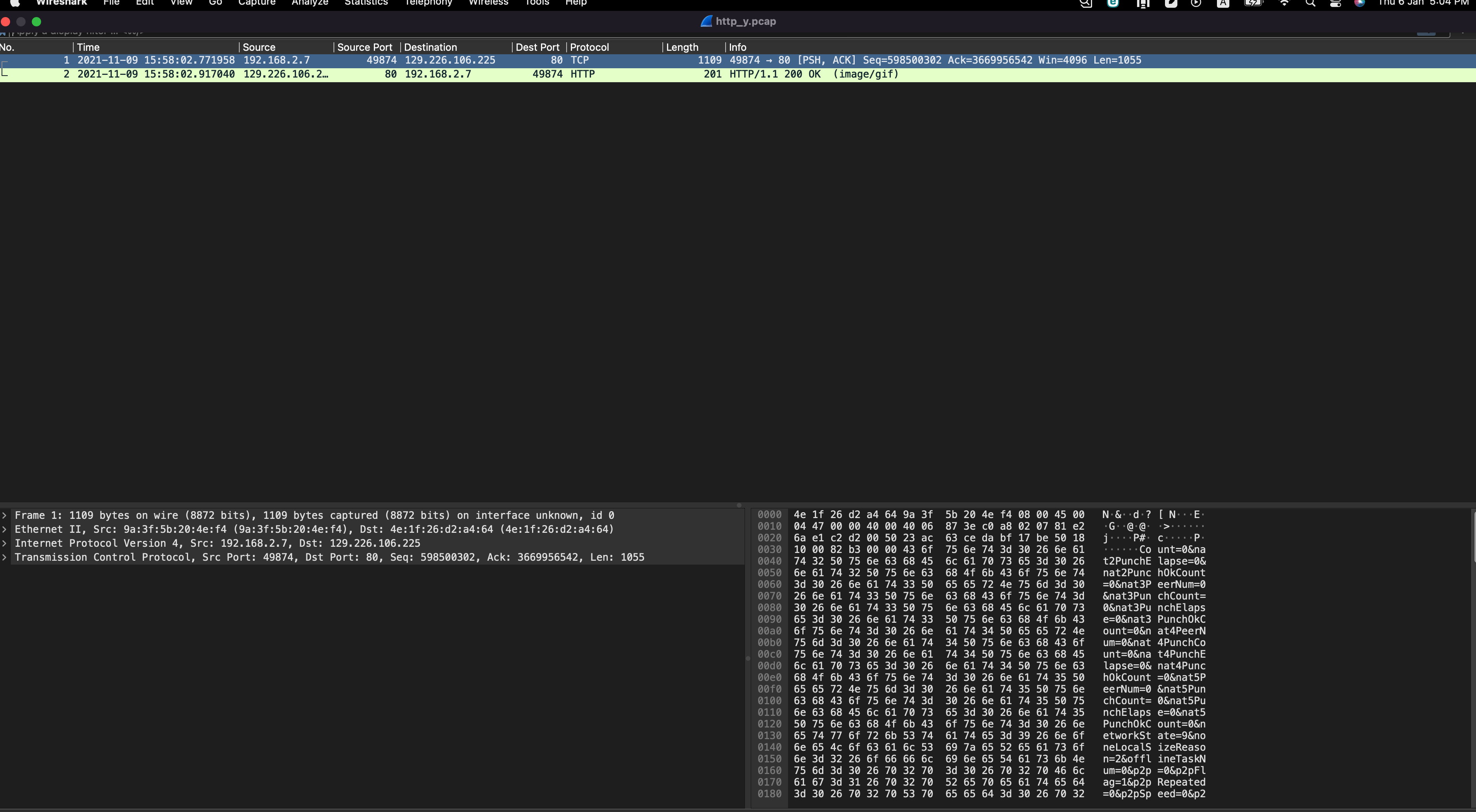
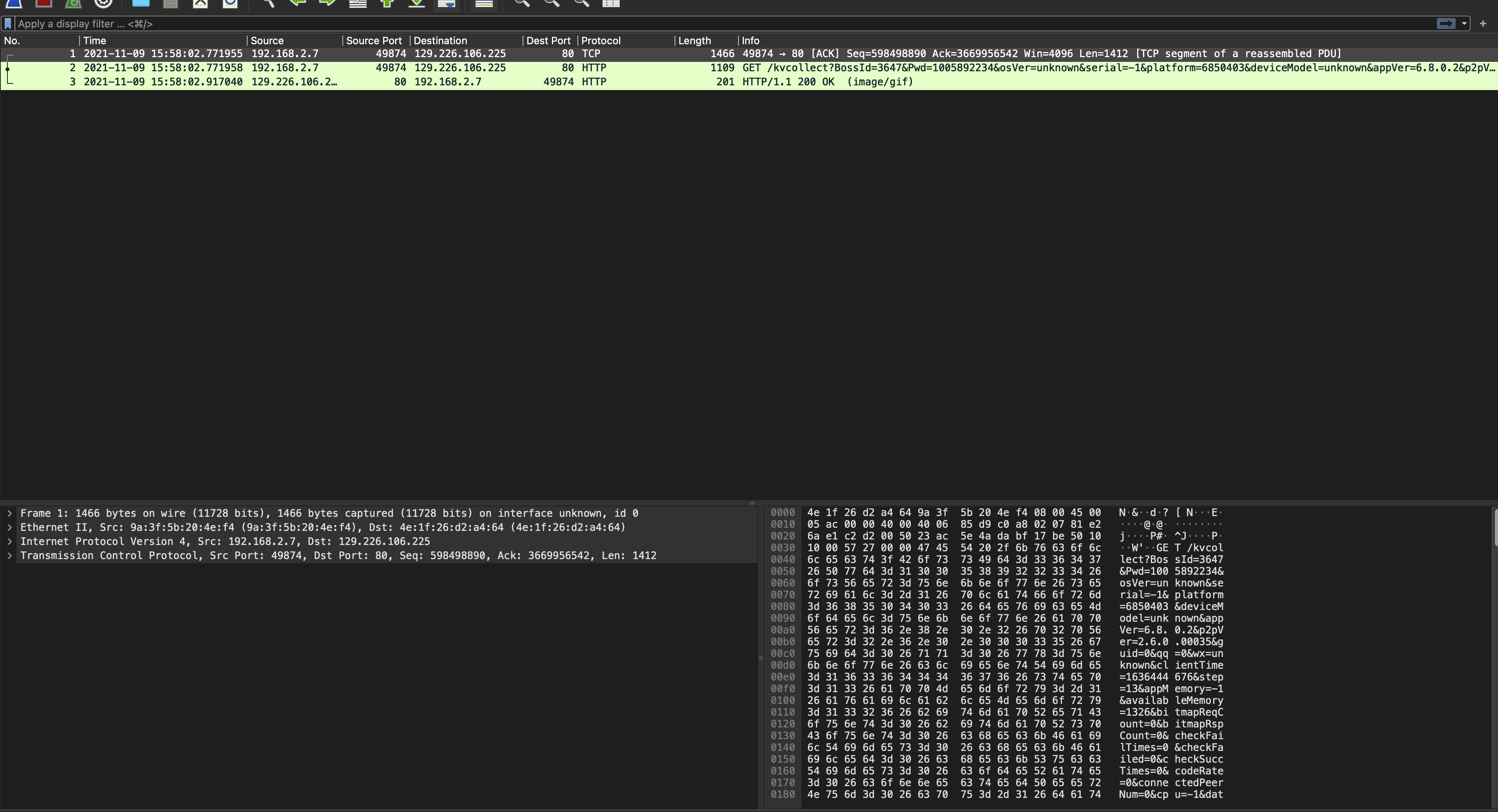
Today I met an interesting bug: A C program behaved differently between debug (gcc -O0) and release (gcc -O3) modes.
First of all, I compared the logs between two modes, and pinned down in which function, the logs began to diverge.
Secondly, I used gdb to debug two programs simultaneously, and checked the variables’ values, then found a variable which had disparate values that would cause two programs enter different branches in a if-else statement. Hmm, this was the root cause.
My gut feeling was the release mode program may fetch the staled value, but after reviewing code carefully, I found the reason is one block memory (the variable belonged to) allocated from heap was not initialised, so this will introduce notorious “undefined behaviour”.
As far as I know, the reasons for uninitialising variables:
(1) The programmer forgets;
(2) The programmer reckons the variable will be assigned correct value before use, and there may be performance penalty for initialising a block of memory.
Anyway, the lesson I learnt today is unless you are 100% sure it will be OK to uninitialise the specified variable, otherwise please initialise it, and this can save you several hours in the future.