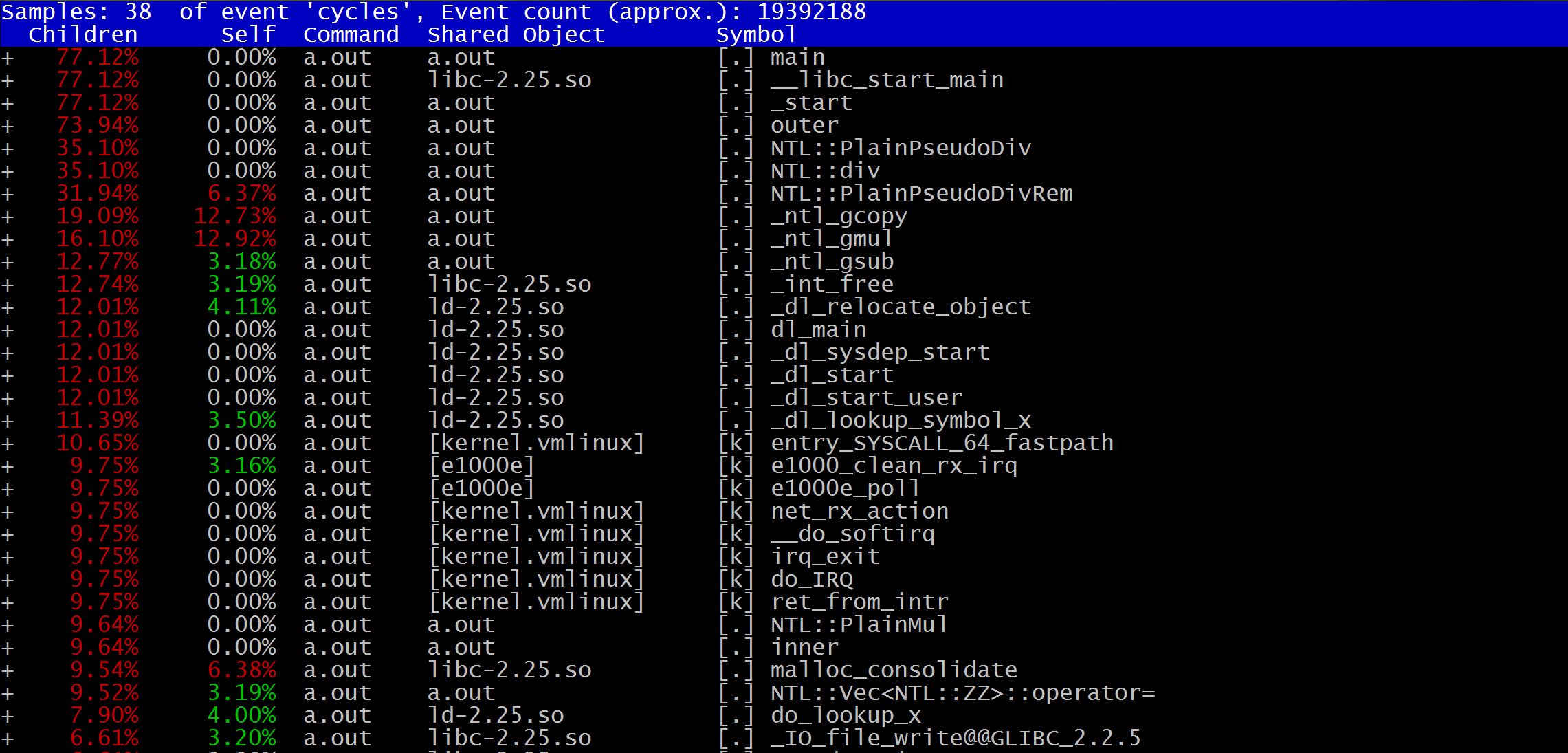
The bcc gives a simple Hello World program analysis, but I want to give a more detailed anatomy of it:
from bcc import BPF
BPF(text='int kprobe__sys_clone(void *ctx) { bpf_trace_printk("Hello, World!\\n"); return 0; }').trace_print()
(1)
from bcc import BPF
bcc is a package, and it will be installed in Python‘s site-packages directory. Take my server as an example:
>>> import bcc
>>> bcc.__path__
['/usr/lib/python3.6/site-packages/bcc']
BPF is a class defined in __init__.py file of bcc:
......
class BPF(object):
# From bpf_prog_type in uapi/linux/bpf.h
SOCKET_FILTER = 1
KPROBE = 2
......
(2) Divide
BPF(text='int kprobe__sys_clone(void *ctx) { bpf_trace_printk("Hello, World!\\n"); return 0; }').trace_print()
into 2 parts:
BPF(text='int kprobe__sys_clone(void *ctx) { bpf_trace_printk("Hello, World!\\n"); return 0; }')
and
trace_print()
a)
BPF(text='int kprobe__sys_clone(void *ctx) { bpf_trace_printk("Hello, World!\\n"); return 0; }')
This statement will create a BPF object, and the code is simplified as following:
......
from .libbcc import lib, _CB_TYPE, bcc_symbol, _SYM_CB_TYPE
......
class BPF(object):
......
def __init__(self, src_file="", hdr_file="", text=None, cb=None, debug=0,
cflags=[], usdt_contexts=[]):
......
if text:
self.module = lib.bpf_module_create_c_from_string(text.encode("ascii"),
self.debug, cflags_array, len(cflags_array))
else:
......
self._trace_autoload()
Check libbcc.py:
lib = ct.CDLL("libbcc.so.0", use_errno=True)
We can see lib module is indeed libbcc dynamic library, and bpf_module_create_c_from_string is implemented as this:
void * bpf_module_create_c_from_string(const char *text, unsigned flags, const char *cflags[], int ncflags) {
auto mod = new ebpf::BPFModule(flags);
if (mod->load_string(text, cflags, ncflags) != 0) {
delete mod;
return nullptr;
}
return mod;
}
We won’t delve it too much, and just know it returns a ebpf module is enough.
For self._trace_autoload() part, we can check _trace_autoload method definition:
def _trace_autoload(self):
for i in range(0, lib.bpf_num_functions(self.module)):
func_name = str(lib.bpf_function_name(self.module, i).decode())
if func_name.startswith("kprobe__"):
fn = self.load_func(func_name, BPF.KPROBE)
self.attach_kprobe(event=fn.name[8:], fn_name=fn.name)
elif func_name.startswith("kretprobe__"):
fn = self.load_func(func_name, BPF.KPROBE)
self.attach_kretprobe(event=fn.name[11:], fn_name=fn.name)
elif func_name.startswith("tracepoint__"):
fn = self.load_func(func_name, BPF.TRACEPOINT)
tp = fn.name[len("tracepoint__"):].replace("__", ":")
self.attach_tracepoint(tp=tp, fn_name=fn.name)
Based on above code, we can see bcc now supports kprobe, kretprobe and tracepoint. For Hello World example, it actually execute attach_kprobemethod:
def attach_kprobe(self, event="", fn_name="", event_re="",
pid=-1, cpu=0, group_fd=-1):
......
event = str(event)
self._check_probe_quota(1)
fn = self.load_func(fn_name, BPF.KPROBE)
ev_name = "p_" + event.replace("+", "_").replace(".", "_")
res = lib.bpf_attach_kprobe(fn.fd, 0, ev_name.encode("ascii"),
event.encode("ascii"), pid, cpu, group_fd,
self._reader_cb_impl, ct.cast(id(self), ct.py_object))
res = ct.cast(res, ct.c_void_p)
......
self._add_kprobe(ev_name, res)
return self
Finally, it will call libbcc‘s bpf_attach_kprobe function. Until now, the kprobe is attached successfully, and attach_kprobe will return a BPF object.
(b)
BPF(...).trace_print()
The trace_print method is not too hard:
def trace_print(self, fmt=None):
......
try:
while True:
if fmt:
fields = self.trace_fields(nonblocking=False)
if not fields: continue
line = fmt.format(*fields)
else:
line = self.trace_readline(nonblocking=False)
print(line)
sys.stdout.flush()
except KeyboardInterrupt:
exit()
For fmt=None case, it just calls trace_readline(), which read from trace pipe, and prints it on the stdout:
print(line)
sys.stdout.flush()
That’s all, and hope you enjoy bcc and ebpf!