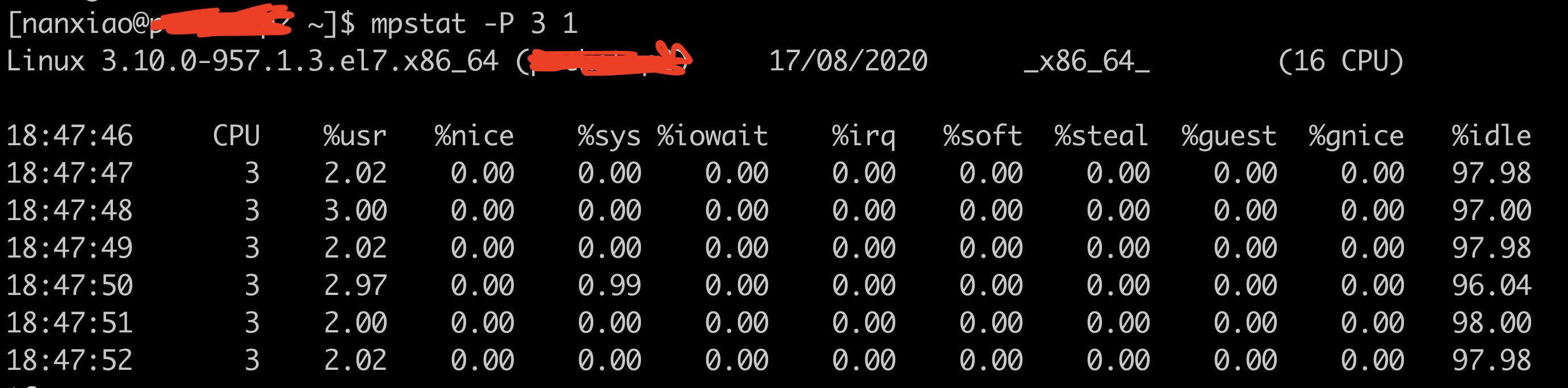
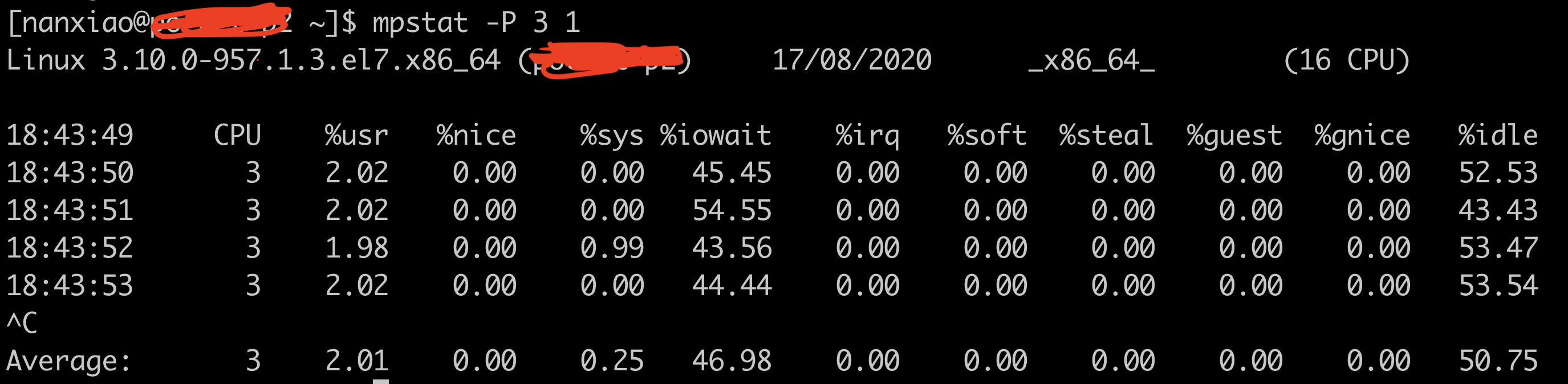
vmstat is a useful tool to check system performance on Unix Operating Systems. The following is its output from illumos:
# vmstat
kthr memory page disk faults cpu
r b w swap free re mf pi po fr de sr ro s0 -- -- in sy cs us sy id
1 0 0 1831316 973680 14 38 0 0 1 0 5314 3 3 0 0 1513 472 391 83 9 7
From the manual, the first column kthr:r’ meaning is:
kthr
Report the number of kernel threads in each of the three following states:
r
the number of kernel threads in run queue
So the question is how to define “run queue” here? After some googling, I find this good post:
The reported operating system run queue includes both processes waiting to be serviced and those currently being serviced.
But from another excerpt from Solaris 9 System Monitoring and Tuning:
The column labeled r under the kthr section is the run queue of processes waiting to get on the CPU(s).
Does illumos‘s run queue include both current running and wait-to-run tasks? I can’t get a clear answer (I know illumos is derived from Solaris, but not sure whether the description in Solaris 9 is still applicable for illumos).
I tried to get help from illumos discussion mailing list, and Joshua gave a detailed explanation. Though he didn’t tell me the final answer, I knew where I should delve into:
(1) The statistic of runque is actually from disp_nrunnable (the code is here):
......
/*
* First count the threads waiting on kpreempt queues in each
* CPU partition.
*/
uint_t cpupart_nrunnable = cpupart->cp_kp_queue.disp_nrunnable;
cpupart->cp_updates++;
nrunnable += cpupart_nrunnable;
......
/* Now count the per-CPU statistics. */
uint_t cpu_nrunnable = cp->cpu_disp->disp_nrunnable;
nrunnable += cpu_nrunnable;
......
if (nrunnable) {
sysinfo.runque += nrunnable;
sysinfo.runocc++;
}
The definition of disp_nrunnable:
/*
* Dispatch queue structure.
*/
typedef struct _disp {
......
volatile int disp_nrunnable; /* runnable threads in cpu dispq */
......
} disp_t;
(2) Checked the code related to disp_nrunnable:
/*
* disp() - find the highest priority thread for this processor to run, and
* set it in TS_ONPROC state so that resume() can be called to run it.
*/
static kthread_t *
disp()
{
......
dq = &dp->disp_q[pri];
tp = dq->dq_first;
......
/*
* Found it so remove it from queue.
*/
dp->disp_nrunnable--;
......
thread_onproc(tp, cpup); /* set t_state to TS_ONPROC */
......
}
Checked definition of TS_ONPROC:
/*
* Values that t_state may assume. Note that t_state cannot have more
* than one of these flags set at a time.
*/
......
#define TS_RUN 0x02 /* Runnable, but not yet on a processor */
#define TS_ONPROC 0x04 /* Thread is being run on a processor */
......
Umm, it became clear: when kernel picks one task to run, removes it from the dispatch queue, decreases disp_nrunnable by 1, and set task’s state as TS_ONPROC. Based on above analysis, illumos‘s run queue should include only wait-to-run tasks, not current running ones.
To verify my thought, I implemented following simple CPU-intensive program:
# cat foo.c
int main(){
while(1);
}
My virtual machine has only 1 CPU. Use vmstat when it is in idle state:
# vmstat 1
kthr memory page disk faults cpu
r b w swap free re mf pi po fr de sr ro s0 -- -- in sy cs us sy id
1 0 0 1829088 970732 8 22 0 0 0 0 2885 1 2 0 0 1523 261 343 85 10 6
0 0 0 1827484 968844 16 53 0 0 0 0 0 0 0 0 0 2173 330 285 0 10 90
0 0 0 1827412 968808 0 1 0 0 0 0 0 0 0 0 0 2177 284 258 0 10 90
0 0 0 1827412 968808 0 0 0 0 0 0 0 0 0 0 0 2167 296 301 0 9 91
0 0 0 1827412 968808 0 0 0 0 0 0 0 0 0 0 0 2173 278 298 0 9 91
0 0 0 1827412 968808 0 0 0 0 0 0 0 0 0 0 0 2173 280 283 0 9 91
0 0 0 1827412 968808 0 0 0 0 0 0 0 0 0 0 0 2175 279 329 0 10 90
......;
kthr:r was 0, and cpu:id (the last column) was more than 90. Launched one instance of foo program:
# ./foo &
[1] 668
Checked vmstat again:
# vmstat 1
kthr memory page disk faults cpu
r b w swap free re mf pi po fr de sr ro s0 -- -- in sy cs us sy id
1 0 0 1829076 970720 8 21 0 0 0 0 2860 1 2 0 0 1528 260 343 84 10 6
0 0 0 1826220 968100 16 53 0 0 0 0 0 0 0 0 0 1550 334 262 90 10 0
0 0 0 1826148 968064 0 1 0 0 0 0 0 0 0 0 0 1399 288 264 91 9 0
0 0 0 1826148 968064 0 0 0 0 0 0 0 0 0 0 0 1283 277 253 92 8 0
0 0 0 1826148 968064 0 0 0 0 0 0 0 0 0 0 0 1367 281 247 91 9 0
0 0 0 1826148 968064 0 0 0 0 0 0 0 0 0 0 0 1420 277 239 91 9 0
0 0 0 1826148 968064 0 0 0 0 0 0 0 0 0 0 0 1371 281 239 91 9 0
0 0 0 1826148 968064 0 0 0 0 0 0 0 0 0 0 0 1289 278 250 92 8 0
......
This time kthr:r was still 0, but cpu:id became 0. Launched another foo:
# ./foo &
[2] 675
Checked vmstat again:
# vmstat 1
kthr memory page disk faults cpu
r b w swap free re mf pi po fr de sr ro s0 -- -- in sy cs us sy id
1 0 0 1828912 970572 7 20 0 0 0 0 2672 1 1 0 0 1518 244 337 84 9 6
1 0 0 1825748 967656 16 53 0 0 0 0 0 0 0 0 0 1554 335 284 90 10 0
1 0 0 1825676 967620 0 1 0 0 0 0 0 0 0 0 0 1497 286 271 90 10 0
1 0 0 1825676 967620 0 0 0 0 0 0 0 0 0 0 0 1387 309 288 92 8 0
2 0 0 1825676 967620 0 0 0 0 0 0 0 0 0 0 0 1643 365 291 90 10 0
1 0 0 1825676 967620 0 0 0 0 0 0 0 0 0 0 0 1446 276 273 91 9 0
1 0 0 1825676 967620 0 0 0 0 0 0 0 0 0 0 0 1325 645 456 92 8 0
1 0 0 1825676 967620 0 0 0 0 0 0 0 0 0 0 0 1375 296 300 91 9 0
kthr:r became 1 (yes, it was 2 once). There were 2 CPU-intensive foo program running, whereas kthr:r‘s value was only 1, it means kthr:r excludes the on-CPU task. I also run another foo process, and as expected, kthr:r became 2.
Finally, the test results proved the statement from Solaris 9 System Monitoring and Tuning is right:
The column labeled r under the kthr section is the run queue of processes waiting to get on the CPU(s).