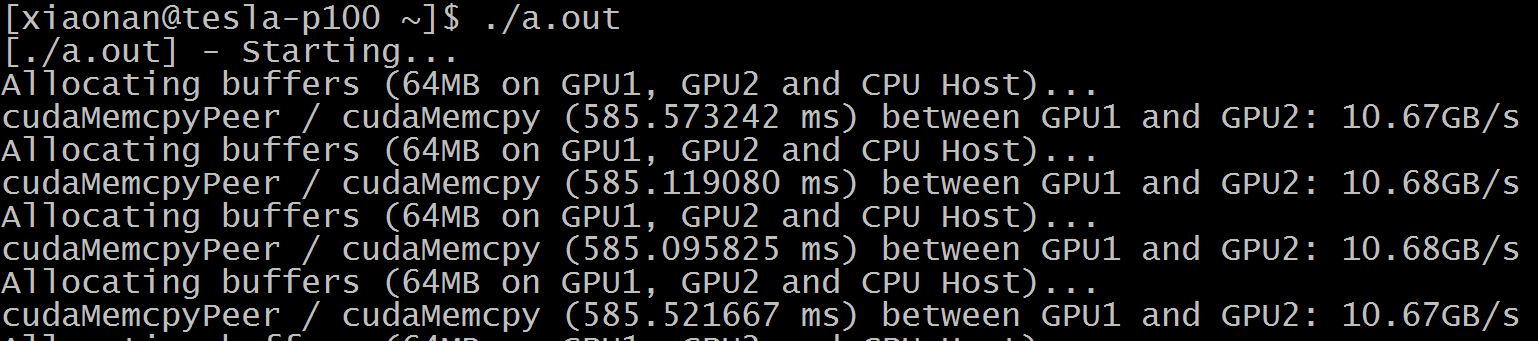
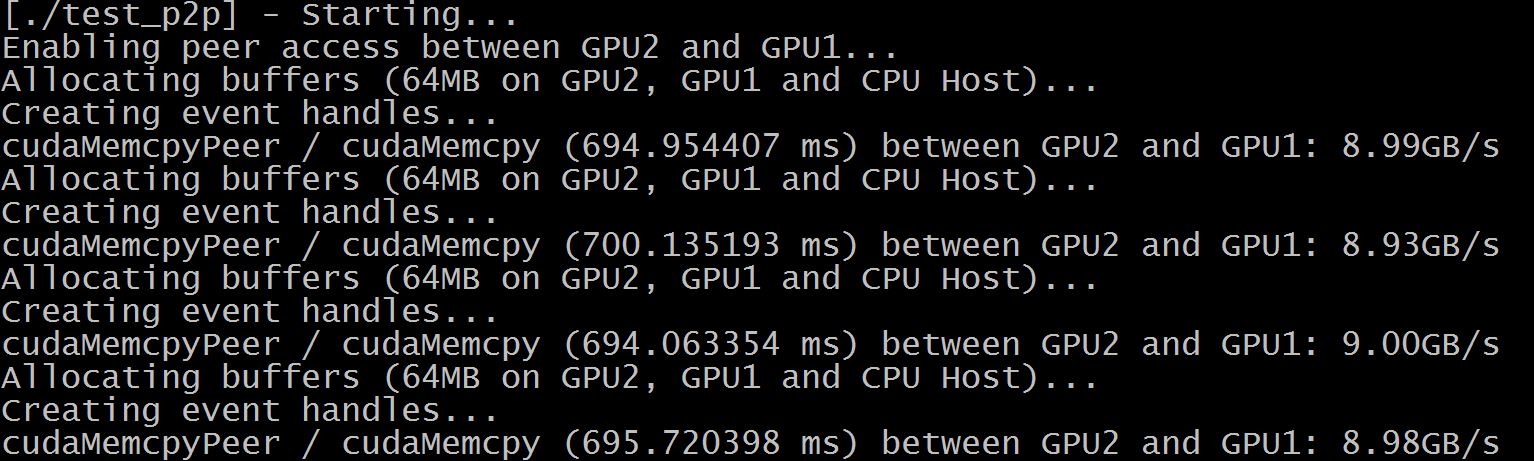
Check following simple program:
cat test_stream.cu
int main()
{
cudaStream_t st_00, st_01, st_11;
cudaSetDevice(0);
cudaStreamCreate(&st_00);
cudaStreamCreate(&st_01);
cudaSetDevice(1);
cudaStreamCreate(&st_11);
return 0;
}
In my system, device 0 is Nvidia Tesla-V100 GPU while device 1 is Tesla-P100. Use cuda-gdb to debug the program step by step:
(1)
Temporary breakpoint 1, main () at /home/xiaonan/temp/test_stream.cu:2
2 {
(cuda-gdb) i threads
Id Target Id Frame
* 1 Thread 0x7ffff7a74740 (LWP 82365) "test_stream" main () at /home/xiaonan/temp/test_stream.cu:2
(cuda-gdb) n
5 cudaSetDevice(0);
(cuda-gdb)
[New Thread 0x7fffdffff700 (LWP 82532)]
6 cudaStreamCreate(&st_00);
(cuda-gdb) i threads
Id Target Id Frame
* 1 Thread 0x7ffff7a74740 (LWP 82365) "test_stream" main () at /home/xiaonan/temp/test_stream.cu:6
2 Thread 0x7fffdffff700 (LWP 82532) "test_stream" 0x00007ffff7b743e7 in accept4 () from /usr/lib/libc.so.6
When the program was launched, there is only main thread (Id is 1). Then after calling cudaSetDevice(0);, a new thread is spawned (Id is 2).
(2)
(cuda-gdb) i threads
Id Target Id Frame
* 1 Thread 0x7ffff7a74740 (LWP 82365) "test_stream" main () at /home/xiaonan/temp/test_stream.cu:6
2 Thread 0x7fffdffff700 (LWP 82532) "test_stream" 0x00007ffff7b743e7 in accept4 () from /usr/lib/libc.so.6
(cuda-gdb) n
[New Thread 0x7fffdf7fe700 (LWP 82652)]
7 cudaStreamCreate(&st_01);
(cuda-gdb) i threads
Id Target Id Frame
* 1 Thread 0x7ffff7a74740 (LWP 82365) "test_stream" main () at /home/xiaonan/temp/test_stream.cu:7
2 Thread 0x7fffdffff700 (LWP 82532) "test_stream" 0x00007ffff7b743e7 in accept4 () from /usr/lib/libc.so.6
3 Thread 0x7fffdf7fe700 (LWP 82652) "test_stream" 0x00007ffff7b67bb1 in poll () from /usr/lib/libc.so.6
On device 0, only first calling cudaStreamCreate will generate a new thread. Check used memory through nvidia-smi command:
$ nvidia-smi
Tue Nov 13 16:53:37 2018
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 410.57 Driver Version: 410.57 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla P100-PCIE... On | 00000000:3B:00.0 Off | 0 |
| N/A 31C P0 29W / 250W | 10MiB / 16280MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 1 Tesla P100-PCIE... On | 00000000:5E:00.0 Off | 0 |
| N/A 26C P0 28W / 250W | 10MiB / 16280MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 2 Tesla P100-PCIE... On | 00000000:AF:00.0 Off | 0 |
| N/A 29C P0 29W / 250W | 10MiB / 16280MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 3 Tesla V100-PCIE... On | 00000000:D8:00.0 Off | 0 |
| N/A 35C P0 47W / 250W | 769MiB / 16130MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 3 82365 C /home/xiaonan/temp/build/test_stream 407MiB |
+-----------------------------------------------------------------------------+
Create another stream, you will find the memory usage is the same as before.
(3)
(cuda-gdb) n
9 cudaSetDevice(1);
(cuda-gdb)
10 cudaStreamCreate(&st_11);
(cuda-gdb)
[New Thread 0x7fffdeffd700 (LWP 82993)]
12 return 0;
(cuda-gdb) i threads
Id Target Id Frame
* 1 Thread 0x7ffff7a74740 (LWP 82365) "test_stream" main () at /home/xiaonan/temp/test_stream.cu:12
2 Thread 0x7fffdffff700 (LWP 82532) "test_stream" 0x00007ffff7b743e7 in accept4 () from /usr/lib/libc.so.6
3 Thread 0x7fffdf7fe700 (LWP 82652) "test_stream" 0x00007ffff7b67bb1 in poll () from /usr/lib/libc.so.6
4 Thread 0x7fffdeffd700 (LWP 82993) "test_stream" 0x00007ffff7b67bb1 in poll () from /usr/lib/libc.so.6
Switch to another device and create stream; check memory usage now:
$ nvidia-smi
Tue Nov 13 16:54:24 2018
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 410.57 Driver Version: 410.57 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla P100-PCIE... On | 00000000:3B:00.0 Off | 0 |
| N/A 31C P0 30W / 250W | 291MiB / 16280MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 1 Tesla P100-PCIE... On | 00000000:5E:00.0 Off | 0 |
| N/A 26C P0 28W / 250W | 10MiB / 16280MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 2 Tesla P100-PCIE... On | 00000000:AF:00.0 Off | 0 |
| N/A 29C P0 29W / 250W | 10MiB / 16280MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 3 Tesla V100-PCIE... On | 00000000:D8:00.0 Off | 0 |
| N/A 35C P0 47W / 250W | 769MiB / 16130MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 82365 C /home/xiaonan/temp/build/test_stream 281MiB |
| 3 82365 C /home/xiaonan/temp/build/test_stream 407MiB |
+-----------------------------------------------------------------------------+
You will find different devices consume different memory for creating streams.